FloatPrecision и FloatMode Burst компилÑтора: Ðе надо гадать
(Russian translation from English by Maxim Voloshin)
Ðовый компилÑтор Unity 2019.1 Ð´Ð»Ñ Job System имеет две опции Ð´Ð»Ñ ÑƒÐ²ÐµÐ»Ð¸Ñ‡ÐµÐ½Ð¸Ñ Ð¿Ñ€Ð¾Ð¸Ð·Ð²Ð¾Ð´Ð¸Ñ‚ÐµÐ»ÑŒÐ½Ð¾Ñти еще Ñильнее: FloatPrecision и FloatMode. Ð–ÐµÑ€Ñ‚Ð²ÑƒÑ Ð½ÐµÐºÐ¾Ñ‚Ð¾Ñ€Ð¾Ð¹ точноÑтью вычиÑлений, мы имеем возможноÑÑ‚ÑŒ увеличить ÑкороÑÑ‚ÑŒ выполнениÑ. СегоднÑшнÑÑ ÑÑ‚Ð°Ñ‚ÑŒÑ Ð¾Ð± иÑÑледовании и проверке результатов иÑÐ¿Ð¾Ð»ÑŒÐ·Ð¾Ð²Ð°Ð½Ð¸Ñ Ñтих опций.
ИÑпользовать FloatPrecision и FloatMode Ñ Burst очень проÑто. ДоÑтаточно заменить Ñто:
[BurstCompile] struct MyJob : IJob
Ðа Ñто:
[BurstCompile(FloatPrecision.High, FloatMode.Strict)] struct MyJob : IJob
Вот как код Ñтих двух перечиÑлений выглÑдÑÑ‚ в Burst 1.0.0:
/// <summary> /// ПредÑтавлÑет Ñобой точноÑÑ‚ÑŒ вычиÑлений Ñ Ð¿Ð»Ð°Ð²Ð°ÑŽÑ‰ÐµÐ¹ точкой Ð´Ð»Ñ Ð¾Ð¿Ñ€ÐµÐ´ÐµÐ»ÐµÐ½Ð½Ñ‹Ñ… вÑтроенных операций, ÑинуÑ/коÑÐ¸Ð½ÑƒÑ Ð¸ Ñ‚.д. /// </summary> public enum FloatPrecision { /// <summary> /// ИÑпользует точноÑÑ‚ÑŒ по умолчанию, Ñмотри FloatPrecision.Medium /// </summary> Standard = 0, /// <summary> /// ВычиÑÐ»ÐµÐ½Ð¸Ñ Ñ Ñ‚Ð¾Ñ‡Ð½Ð¾Ñтью до 1 ULP - очень точные, но медленнее выполнÑÑŽÑ‚ÑÑ, не должны иÑпользоватьÑÑ Ð´Ð»Ñ Ð±Ð¾Ð»ÑŒÑˆÐ¸Ð½Ñтва целей /// </summary> High = 1, /// <summary> /// ВычиÑÐ»ÐµÐ½Ð¸Ñ Ñ Ñ‚Ð¾Ñ‡Ð½Ð¾Ñтью 3.5 ULP - ÑчитаютÑÑ Ð¿Ñ€Ð¸ÐµÐ¼Ð»ÐµÐ¼Ñ‹Ð¼Ð¸ Ð´Ð»Ñ Ð±Ð¾Ð»ÑŒÑˆÐ¸Ð½Ñтва задач. /// </summary> Medium = 2, /// <summary> /// Зарезервировано на будущее /// </summary> Low = 3, } /// <summary> /// ПредÑтавлÑет Ñобой режим оптимизаций компилÑтора Ð´Ð»Ñ Ð²Ñ‹Ñ‡Ð¸Ñлений Ñ Ð¿Ð»Ð°Ð²Ð°ÑŽÑ‰ÐµÐ¹ точкой /// </summary> public enum FloatMode { /// <summary> /// ИÑпользует режим по умолчанию, Ñмотри FloatMode.Strict. /// </summary> Default = 0, /// <summary> /// Ðе выполнÑетÑÑ Ð½Ð¸ÐºÐ°ÐºÐ¸Ñ… оптимизаций /// </summary> Strict = 1, /// <summary> /// Зарезервировано на будущее /// </summary> Deterministic = 2, /// <summary> /// ДопуÑкает алгебраичеÑкий Ñквивалент оптимизации (который может поменÑÑ‚ÑŒ результат вычиÑлений), Ñто подразумевает, что: /// <para/> оптимизации могут предполагать, что результаты и аргументы не Ñодержат NaN или +/- беÑконечноÑÑ‚ÑŒ и не учитывают знак нулÑ. /// <para/> оптимизации могут иÑпользовать обратные операции - 1/x * y, вмеÑто y/x. /// <para/> оптимизации могут иÑпользовать Ñовмещенные инÑтрукции, например, madd. /// </summary> Fast = 3, }
Обратите внимание, что каждое перечиÑление Ñодержит четыре конÑтанты, но только две из них имеют какие-то значениÑ. FloatPrecision Ñодержит High и Medium. FloatMode Ñодержит Strict и Fast. Одна из двух других Ñто пÑевдоним Default и конÑтанта Ð·Ð°Ñ€ÐµÐ·ÐµÑ€Ð²Ð¸Ñ€Ð¾Ð²Ð°Ð½Ð½Ð°Ñ Ð½Ð° будущее.
Теперь давайте попробуем иÑпользовать Ñти наÑтройки и поÑмотреть как много производительноÑти мы можем получить от Medium и Fast опций в Ñравнение Ñ High и Strict. Чтобы Ñделать Ñто, мы Ñоздадим задачу, ÐºÐ¾Ñ‚Ð¾Ñ€Ð°Ñ Ñкладывает float4 векторы из двух NativeArray и помещает результат в третий. Затем, мы Ñоздадим задачу, котораÑ, вмеÑто ÑложениÑ, находит ÑкалÑрное произведение. Ð”Ð»Ñ ÐºÐ°Ð¶Ð´Ð¾Ð¹ из них, мы Ñоздадим четыре верÑии: High и Strict, High и Fast, Medium и Strict, Medium и Fast. Вот как выглÑдит теÑтовый Ñкрипт:
using System; using System.Diagnostics; using Unity.Burst; using Unity.Collections; using Unity.Jobs; using Unity.Mathematics; using UnityEngine; class TestScript : MonoBehaviour { [BurstCompile(FloatPrecision.High, FloatMode.Strict)] struct AddHighStrictJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] + B[i]; } } } [BurstCompile(FloatPrecision.High, FloatMode.Fast)] struct AddHighFastJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] + B[i]; } } } [BurstCompile(FloatPrecision.Medium, FloatMode.Strict)] struct AddMedStrictJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] + B[i]; } } } [BurstCompile(FloatPrecision.Medium, FloatMode.Fast)] struct AddMedFastJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] + B[i]; } } } [BurstCompile(FloatPrecision.High, FloatMode.Strict)] struct DotHighStrictJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = math.dot(A[i], B[i]); } } } [BurstCompile(FloatPrecision.High, FloatMode.Fast)] struct DotHighFastJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = math.dot(A[i], B[i]); } } } [BurstCompile(FloatPrecision.Medium, FloatMode.Strict)] struct DotMedStrictJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = math.dot(A[i], B[i]); } } } [BurstCompile(FloatPrecision.Medium, FloatMode.Fast)] struct DotMedFastJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = math.dot(A[i], B[i]); } } } void Start() { const int size = 1000000; const Allocator alloc = Allocator.TempJob; NativeArray<float4> a = new NativeArray<float4>(size, alloc); NativeArray<float4> b = new NativeArray<float4>(size, alloc); NativeArray<float4> c = new NativeArray<float4>(size, alloc); for (int i = 0; i < size; ++i) { a[i] = float4.zero; b[i] = float4.zero; c[i] = float4.zero; } AddHighStrictJob ahsj = new AddHighStrictJob { A = a, B = b, C = c }; AddHighFastJob ahfj = new AddHighFastJob { A = a, B = b, C = c }; AddMedStrictJob amsj = new AddMedStrictJob { A = a, B = b, C = c }; AddMedFastJob amfj = new AddMedFastJob { A = a, B = b, C = c }; DotHighStrictJob dhsj = new DotHighStrictJob { A = a, B = b, C = c }; DotHighFastJob dhfj = new DotHighFastJob { A = a, B = b, C = c }; DotMedStrictJob dmsj = new DotMedStrictJob { A = a, B = b, C = c }; DotMedFastJob dmfj = new DotMedFastJob { A = a, B = b, C = c }; const int reps = 100; long[] ahst = new long[reps]; long[] ahft = new long[reps]; long[] amst = new long[reps]; long[] amft = new long[reps]; long[] dhst = new long[reps]; long[] dhft = new long[reps]; long[] dmst = new long[reps]; long[] dmft = new long[reps]; Stopwatch sw = new Stopwatch(); for (int i = 0; i < reps; ++i) { sw.Restart(); ahsj.Run(); ahst[i] = sw.ElapsedTicks; sw.Restart(); ahfj.Run(); ahft[i] = sw.ElapsedTicks; sw.Restart(); amsj.Run(); amst[i] = sw.ElapsedTicks; sw.Restart(); amfj.Run(); amft[i] = sw.ElapsedTicks; sw.Restart(); dhsj.Run(); dhst[i] = sw.ElapsedTicks; sw.Restart(); dhfj.Run(); dhft[i] = sw.ElapsedTicks; sw.Restart(); dmsj.Run(); dmst[i] = sw.ElapsedTicks; sw.Restart(); dmfj.Run(); dmft[i] = sw.ElapsedTicks; } print( "Operation,High-Strict,High-Fast,Medium-Strict,Medium-Fastn" + "Add," + Median(ahst) + "," + Median(ahft) + "," + Median(amst) + "," + Median(amft) + "n" + "Dot," + Median(dhst) + "," + Median(dhft) + "," + Median(dmst) + "," + Median(dmft)); a.Dispose(); b.Dispose(); c.Dispose(); Application.Quit(); } static long Median(long[] values) { Array.Sort(values); return values[values.Length / 2]; } }
Теперь давайте попробуем запуÑтить теÑтовый Ñкрипт и поÑмотреть какую производительноÑÑ‚ÑŒ мы получим. Я запуÑтил его вот в таком окружении:
- 2.7 Ghz Intel Core i7-6820HQ
- macOS 10.14.4
- Unity 2019.1.0f2
- macOS Standalone
- .NET 4.x scripting runtime version и API compatibility level
- IL2CPP
- Non-development
- 640×480, Fastest, Windowed
И вот результаты, которые Ñ Ð¿Ð¾Ð»ÑƒÑ‡Ð¸Ð»:
| Operation | High-Strict | High-Fast | Medium-Strict | Medium-Fast |
|---|---|---|---|---|
| Add | 26920 | 26790 | 26520 | 26510 |
| Dot | 28810 | 29020 | 29080 | 29150 |
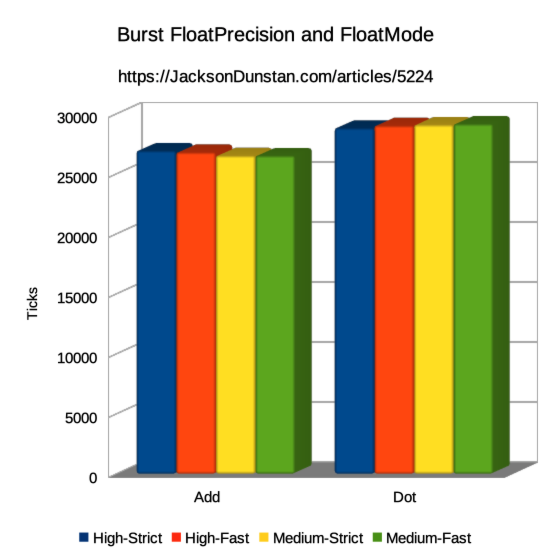
Сразу видно, что при иÑпользовании разных наÑтроек FloatPrecision и FloatMode ни один из результатов не Ñовпал. График показывает небольшой уклон Ð´Ð»Ñ ÑÐ»Ð¾Ð¶ÐµÐ½Ð¸Ñ Ð¸ небольшой подъем Ð´Ð»Ñ ÑкалÑрного произведениÑ. ЕÑли Ñравнивать Ñамое медленное Ñ Ñамым быÑтрым, то мы получим выигрыш в производительноÑти 1.5% Ð´Ð»Ñ ÑÐ»Ð¾Ð¶ÐµÐ½Ð¸Ñ Ð¸ Ñнижение производительноÑти в 1.2% Ð´Ð»Ñ ÑкалÑрного произведениÑ.
Ðа данный момент мы можем Ñделать выводы, что Ñти наÑтройки могут только незначительно повлиÑÑ‚ÑŒ на результат, который, к тому же, отличаетÑÑ Ð´Ð»Ñ Ñ€Ð°Ð·Ð½Ñ‹Ñ… операций: что-то быÑтрее, а что-то медленнее. Однако, Ñти выводы неверны. Почему? Давайте поÑмотрим в Burst Inspector Ð´Ð»Ñ Ñ‚Ð¾Ð³Ð¾, чтобы увидеть аÑÑемблерный код, в который были Ñкомпилированы наши задачи. Вот Ñтот код:
; High-Strict movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] addps xmm1, xmm0 movups xmmword ptr [rsi + rdi], xmm1 ; High-Fast movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] addps xmm1, xmm0 movups xmmword ptr [rsi + rdi], xmm1 ; Medium-Strict movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] addps xmm1, xmm0 movups xmmword ptr [rsi + rdi], xmm1 ; Medium-Fast movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] addps xmm1, xmm0 movups xmmword ptr [rsi + rdi], xmm1
И вот как было Ñкомпилировано ÑкалÑрное произведение:
; High-Strict movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] mulps xmm1, xmm0 movshdup xmm0, xmm1 addps xmm1, xmm0 movhlps xmm0, xmm1 addps xmm0, xmm1 shufps xmm0, xmm0, 0 movups xmmword ptr [rsi + rdi], xmm0 ; High-Fast movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] mulps xmm1, xmm0 movshdup xmm0, xmm1 addps xmm1, xmm0 movhlps xmm0, xmm1 addps xmm0, xmm1 shufps xmm0, xmm0, 0 movups xmmword ptr [rsi + rdi], xmm0 ; Medium-Strict movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] mulps xmm1, xmm0 movshdup xmm0, xmm1 addps xmm1, xmm0 movhlps xmm0, xmm1 addps xmm0, xmm1 shufps xmm0, xmm0, 0 movups xmmword ptr [rsi + rdi], xmm0 ; Medium-Fast movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] mulps xmm1, xmm0 movshdup xmm0, xmm1 addps xmm1, xmm0 movhlps xmm0, xmm1 addps xmm0, xmm1 shufps xmm0, xmm0, 0 movups xmmword ptr [rsi + rdi], xmm0
Вам не нужно знать ÐÑÑемблер, чтобы понÑÑ‚ÑŒ, что вÑе задачи были Ñкомпилированы в абÑолютно идентичный код. FloatPrecision и FloatMode не имеют ни малейшего Ñффекта на задачи. Они не делают задачи иногда быÑтрее или медленнее, они вообще ничего не делают.
Из вÑего Ñтого нужно вынеÑти пару уроков. Во-первых, проÑто поÑмотреть на результат замеров производительноÑти не доÑтаточно, чтобы окончательно Ñделать вывод о том, как что-то работает. ЧиÑла и график показывают, что производительноÑÑ‚ÑŒ увеличиваетÑÑ Ð¸ уменьшаетÑÑ, но Ñто еще не вÑе. Ðам нужно получить одинаковую информацию из неÑкольких иÑточников, что бы по-наÑтоÑщему понÑÑ‚ÑŒ как что-то работает. Ð’ данном Ñлучае, Burst Inspector раÑкрыл нам глаза и показал, что вÑе, что мы видели в замере производительноÑти еÑÑ‚ÑŒ погрешноÑÑ‚ÑŒ измерений.
Во-вторых, FloatPrecision и FloatMode Ñовершенно ни на что не влиÑÑŽÑ‚. Я не проверÑл вÑе 1840 методов клаÑÑа math и Ñ‚Ñ‹ÑÑчи перегрузок операторов вÑех типов в Unity.Mathematics, и, возможно, иногда Ñти наÑтройки будут на что-то влиÑÑ‚ÑŒ. Ðо Ð´Ð»Ñ Ñтих конкретных операций float4+float4 и dot(float4, float4) нет никакой разницы. Лучше вÑего приÑлушатьÑÑ Ðº Ñовету выше в коде Вашей ÑобÑтвенной игры. ИÑпользование Burst Inspector в комбинации Ñ Ð·Ð°Ð¼ÐµÑ€Ð°Ð¼Ð¸ производительноÑти даÑÑ‚ более полную картину того, как работает именно ваш код и поможет принÑÑ‚ÑŒ лучшее техничеÑкое решение.