Burst’s FloatPrecision and FloatMode: Don’t Assume
Unity 2019.1’s new Burst job compiler has two options to increase performance even further: FloatPrecision and FloatMode. By sacrificing some exactness in our calculations, we should be able to increase speed. Today’s article is about using those options and examining the results to verify the results.
Update: A Russian translation of this article is available.
Using Burst’s FloatPrecision and FloatMode settings is easy. Just replace this:
[BurstCompile] struct MyJob : IJob
With this:
[BurstCompile(FloatPrecision.High, FloatMode.Strict)] struct MyJob : IJob
Here’s how those two enums look in the Burst 1.0.0 package:
/// <summary> /// Represents the floating point precision used for certain builtin operations e.g. sin/cos. /// </summary> public enum FloatPrecision { /// <summary> /// Use the default target floating point precision - <see cref="FloatPrecision.Medium"/>. /// </summary> Standard = 0, /// <summary> /// Compute with an accuracy of 1 ULP - highly accurate, but increased runtime as a result, should not be required for most purposes. /// </summary> High = 1, /// <summary> /// Compute with an accuracy of 3.5 ULP - considered acceptable accuracy for most tasks. /// </summary> Medium = 2, /// <summary> /// Reserved for future. /// </summary> Low = 3, } /// <summary> /// Represents the floating point optimization mode for compilation. /// </summary> public enum FloatMode { /// <summary> /// Use the default target floating point mode - <see cref="FloatMode.Strict"/>. /// </summary> Default = 0, /// <summary> /// No floating point optimizations are performed. /// </summary> Strict = 1, /// <summary> /// Reserved for future. /// </summary> Deterministic = 2, /// <summary> /// Allows algebraically equivalent optimizations (which can alter the results of calculations), it implies : /// <para/> optimizations can assume results and arguments contain no NaNs or +/- Infinity and treat sign of zero as insignificant. /// <para/> optimizations can use reciprocals - 1/x * y , instead of y/x. /// <para/> optimizations can use fused instructions, e.g. madd. /// </summary> Fast = 3, }
Notice that each enum has four enumerators, but only two currently have any meaning. FloatPrecision has High and Medium. FloatMode has Strict and Fast. The others are either a Default alias or an enumerator reserved for the future.
Now let’s try using these settings to see how much performance we can get out of the Medium and Fast options compared to High and Strict. To do that, we’ll create a job that adds together float4 vectors in two NativeArray<float4> and stores the result in a third. Then we’ll create a job that performs a dot product instead of adding. For each of these, we’ll create four versions: High and Strict, High and Fast, Medium and Strict, and Medium and Fast. Here’s how the test script looks:
using System; using System.Diagnostics; using Unity.Burst; using Unity.Collections; using Unity.Jobs; using Unity.Mathematics; using UnityEngine; class TestScript : MonoBehaviour { [BurstCompile(FloatPrecision.High, FloatMode.Strict)] struct AddHighStrictJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] + B[i]; } } } [BurstCompile(FloatPrecision.High, FloatMode.Fast)] struct AddHighFastJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] + B[i]; } } } [BurstCompile(FloatPrecision.Medium, FloatMode.Strict)] struct AddMedStrictJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] + B[i]; } } } [BurstCompile(FloatPrecision.Medium, FloatMode.Fast)] struct AddMedFastJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] + B[i]; } } } [BurstCompile(FloatPrecision.High, FloatMode.Strict)] struct DotHighStrictJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = math.dot(A[i], B[i]); } } } [BurstCompile(FloatPrecision.High, FloatMode.Fast)] struct DotHighFastJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = math.dot(A[i], B[i]); } } } [BurstCompile(FloatPrecision.Medium, FloatMode.Strict)] struct DotMedStrictJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = math.dot(A[i], B[i]); } } } [BurstCompile(FloatPrecision.Medium, FloatMode.Fast)] struct DotMedFastJob : IJob { public NativeArray<float4> A; public NativeArray<float4> B; public NativeArray<float4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = math.dot(A[i], B[i]); } } } void Start() { const int size = 1000000; const Allocator alloc = Allocator.TempJob; NativeArray<float4> a = new NativeArray<float4>(size, alloc); NativeArray<float4> b = new NativeArray<float4>(size, alloc); NativeArray<float4> c = new NativeArray<float4>(size, alloc); for (int i = 0; i < size; ++i) { a[i] = float4.zero; b[i] = float4.zero; c[i] = float4.zero; } AddHighStrictJob ahsj = new AddHighStrictJob { A = a, B = b, C = c }; AddHighFastJob ahfj = new AddHighFastJob { A = a, B = b, C = c }; AddMedStrictJob amsj = new AddMedStrictJob { A = a, B = b, C = c }; AddMedFastJob amfj = new AddMedFastJob { A = a, B = b, C = c }; DotHighStrictJob dhsj = new DotHighStrictJob { A = a, B = b, C = c }; DotHighFastJob dhfj = new DotHighFastJob { A = a, B = b, C = c }; DotMedStrictJob dmsj = new DotMedStrictJob { A = a, B = b, C = c }; DotMedFastJob dmfj = new DotMedFastJob { A = a, B = b, C = c }; const int reps = 100; long[] ahst = new long[reps]; long[] ahft = new long[reps]; long[] amst = new long[reps]; long[] amft = new long[reps]; long[] dhst = new long[reps]; long[] dhft = new long[reps]; long[] dmst = new long[reps]; long[] dmft = new long[reps]; Stopwatch sw = new Stopwatch(); for (int i = 0; i < reps; ++i) { sw.Restart(); ahsj.Run(); ahst[i] = sw.ElapsedTicks; sw.Restart(); ahfj.Run(); ahft[i] = sw.ElapsedTicks; sw.Restart(); amsj.Run(); amst[i] = sw.ElapsedTicks; sw.Restart(); amfj.Run(); amft[i] = sw.ElapsedTicks; sw.Restart(); dhsj.Run(); dhst[i] = sw.ElapsedTicks; sw.Restart(); dhfj.Run(); dhft[i] = sw.ElapsedTicks; sw.Restart(); dmsj.Run(); dmst[i] = sw.ElapsedTicks; sw.Restart(); dmfj.Run(); dmft[i] = sw.ElapsedTicks; } print( "Operation,High-Strict,High-Fast,Medium-Strict,Medium-Fastn" + "Add," + Median(ahst) + "," + Median(ahft) + "," + Median(amst) + "," + Median(amft) + "n" + "Dot," + Median(dhst) + "," + Median(dhft) + "," + Median(dmst) + "," + Median(dmft)); a.Dispose(); b.Dispose(); c.Dispose(); Application.Quit(); } static long Median(long[] values) { Array.Sort(values); return values[values.Length / 2]; } }
Now let’s try running the test script and see what kind of performance we get. I ran it using this environment:
- 2.7 Ghz Intel Core i7-6820HQ
- macOS 10.14.4
- Unity 2019.1.0f2
- macOS Standalone
- .NET 4.x scripting runtime version and API compatibility level
- IL2CPP
- Non-development
- 640×480, Fastest, Windowed
And here are the results I got:
| Operation | High-Strict | High-Fast | Medium-Strict | Medium-Fast |
|---|---|---|---|---|
| Add | 26920 | 26790 | 26520 | 26510 |
| Dot | 28810 | 29020 | 29080 | 29150 |
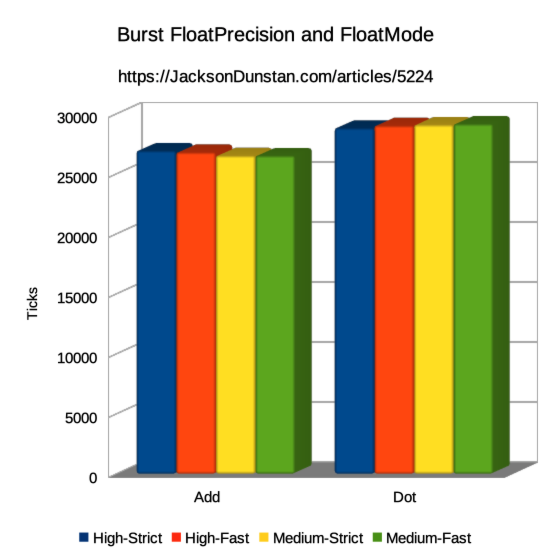
Right off the bat we can see that none of the numbers are quite the same across the FloatPrecision and FloatMode settings. The graph shows a slight downward slope for addition and a slight upward slope for the dot product. Comparing the slowest and the fastest, we see a 1.5% performance increase with addition and a 1.2% performance decrease with the dot product.
At this point we could conclude that these settings only make a small difference and the results are a mixed bag: sometimes it’s faster and sometimes its slower. However, both of these conclusions would be incorrect. Why? To find out, let’s look at the Burst Inspector to see what assembly it compiled the jobs to. Here’s addition:
; High-Strict movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] addps xmm1, xmm0 movups xmmword ptr [rsi + rdi], xmm1 ; High-Fast movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] addps xmm1, xmm0 movups xmmword ptr [rsi + rdi], xmm1 ; Medium-Strict movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] addps xmm1, xmm0 movups xmmword ptr [rsi + rdi], xmm1 ; Medium-Fast movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] addps xmm1, xmm0 movups xmmword ptr [rsi + rdi], xmm1
And here’s how the dot product jobs got compiled:
; High-Strict movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] mulps xmm1, xmm0 movshdup xmm0, xmm1 addps xmm1, xmm0 movhlps xmm0, xmm1 addps xmm0, xmm1 shufps xmm0, xmm0, 0 movups xmmword ptr [rsi + rdi], xmm0 ; High-Fast movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] mulps xmm1, xmm0 movshdup xmm0, xmm1 addps xmm1, xmm0 movhlps xmm0, xmm1 addps xmm0, xmm1 shufps xmm0, xmm0, 0 movups xmmword ptr [rsi + rdi], xmm0 ; Medium-Strict movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] mulps xmm1, xmm0 movshdup xmm0, xmm1 addps xmm1, xmm0 movhlps xmm0, xmm1 addps xmm0, xmm1 shufps xmm0, xmm0, 0 movups xmmword ptr [rsi + rdi], xmm0 ; Medium-Fast movups xmm0, xmmword ptr [rcx + rdi] movups xmm1, xmmword ptr [rdx + rdi] mulps xmm1, xmm0 movshdup xmm0, xmm1 addps xmm1, xmm0 movhlps xmm0, xmm1 addps xmm0, xmm1 shufps xmm0, xmm0, 0 movups xmmword ptr [rsi + rdi], xmm0
You don’t need to know assembly code to see that every one of the jobs was compiled to the same assembly code. FloatPrecision and FloatMode didn’t have a small effect on the jobs, they had zero effect. They didn’t sometimes make the job faster and sometimes make it slower, they were neither faster nor slower at all.
There are a couple of lessons here. First, just looking at the results of a performance test isn’t enough to reach definitive explanations for how something works. The numbers and the graphs showed us performance increases and decreases, but that wasn’t the whole story. We need to confirm with multiple sources to really know how things work. In this case, the Burst Inspector showed us the truth and revealed that all we were seeing in the performance test was statistical noise.
Second, Burst’s FloatPrecision and FloatMode don’t necessarily have any effect at all. I haven’t tested all 1,840 methods of the math class and the thousands of overloaded operators of all the types in Unity.Mathematics, so these settings may have some effect sometimes. For these two particular operations—float4+float4 and dot(float4, float4)—there was no effect. What’s best is to heed the above advice with your own game’s code. Using the Burst Inspector in conjunction with performance tests will give a more complete picture with which you can understand how your game works and make good technical decisions.
#1 by Yilmaz Kiymaz on May 13th, 2019 ·
Hey, thanks for this informative and cautionary post.
Did you reach out to anyone from Unity to find out why these options have no effect in this case? Or in which cases they *do* have an effect?
#2 by jackson on May 14th, 2019 ·
No, as mentioned by Belfegnar below, these options aren’t actually implemented yet despite the presence in the API and the comments to the contrary. The point of the article is not to assume based on these and the performance test results but to really confirm with other sources such as the documentation and the Burst Inspector.
#3 by Belfegnar on May 14th, 2019 ·
At the bottom of the official documentation page, you can see “known issues”: “Accuracy/Precision are currently not supported”
https://docs.unity3d.com/Packages/com.unity.burst@0.2/manual/index.html
#4 by jackson on May 14th, 2019 ·
That’s exactly the point of the article: just because you see some options in an API and get performance test results when using them, you still shouldn’t assume that they are actually doing anything.
#5 by David Wu on May 15th, 2019 ·
I think that you should do more computation per item, otherwise you will always be memory bottlenecked.
#6 by jackson on May 16th, 2019 ·
That’s true and was covered in the previous article.
#7 by Eduardo on June 6th, 2020 ·
Old topic, but relevant for some tests.
Unity 2019.3.14, Burst 1.3
Job task with some vect simple calculations, that also includes some math.length (aka, involves sqrts).
I measured ticks on each frame, and got the average.
What’s important is just de diff between each condition.
ParallelFor Job, but no burst at all
8050
ParallelFor Job, Struct with just [BurstCompile]
3200
ParallelFor Job, Struct with [BurstCompile(FloatPrecision.Low, FloatMode.Fast)]
493
Precision loss for my use case was not relevant.
I’ll check it in the future