Thread Synchronization Performance
Multi-threading is essential to performance on all modern processors. Using multiple threads brings along with it the challenge of synchronizing data access across those threads. Unity’s job system can do some of this for us, but it certainly doesn’t handle every case. For times when it doesn’t, C# provides us with a bunch of synchronization options. Which are fastest? Today we’ll find out!
Setting a Baseline
Today we’ll be comparing various synchronization mechanisms. In order to make sense of their performance, we’ll need to first set a baseline. This will be a test that doesn’t do any synchronization at all. Here’s how it looks
class TestScript : MonoBehaviour { volatile int Value; const int reps = 1000000; void NoSync() { for (int i = 0; i < reps; ++i) { Value++; } } }
The Value variable is the data that our threads will contend for. In a real game, this would be a much larger and more complicated set of data. For the purposes of today’s test, it’s just a single integer. As always, make sure to test with realistic data for the most accurate results.
Note that Value is volatile. This defeats various compiler optimizations such as replacing the loop with Value += reps. We want to keep the loop so that we can repeatedly access Value and generate enough work to be measurable in the performance test.
Speaking of the performance test, we now need to add a little bit of framework to run NoSync:
class TestScript : MonoBehaviour { volatile int Value; const int reps = 1000000; void Start() { StringBuilder report = new StringBuilder(4096); report.AppendLine("Test,IsCorrect,One Thread Ticks,Two Thread Ticks"); Stopwatch sw = Stopwatch.StartNew(); Test(sw, report, "No Sync", NoSync); print(report); } void Test(Stopwatch sw, StringBuilder report, string label, ThreadStart t) { Thread threadA = new Thread(t); Value = 0; sw.Restart(); threadA.Start(); threadA.Join(); long oneThreadTicks = sw.ElapsedTicks; Thread threadB = new Thread(t); Thread threadC = new Thread(t); Value = 0; sw.Restart(); threadB.Start(); threadC.Start(); threadB.Join(); threadC.Join(); long twoThreadTicks = sw.ElapsedTicks; report .Append(label).Append(',') .Append(Value == reps*2).Append(',') .Append(oneThreadTicks).Append(',') .Append(twoThreadTicks).Append('n'); } void NoSync() { for (int i = 0; i < reps; ++i) { Value++; } } }
Start calls Test with each kind of synchronization. Currently, that’s just NoSync but we’ll soon be adding more test functions.
Test runs the test function as a thread in two ways. First, it runs it on the only thread accessing Value. Second, it runs it on two threads so there’s some contention between them for Value. It then adds a row to the CSV report.
Lock Statements
Perhaps the simplest form of synchronization is built right into C#: lock statements. Here’s how it looks:
readonly object lockObject = new object(); void lockStatement() { for (int i = 0; i < reps; ++i) { lock (lockObject) { Value++; } } }
All we needed to add was a lockObject which can be any object. A readonly plain object is a good choice so it doesn’t accidentally get re-assigned or used for anything else.
Then we just add lock (lockObject) around the access to the data being shared between threads: Value++. This compiles to something like this code:
bool __lockWasTaken = false; try { System.Threading.Monitor.Enter(lockObject, ref __lockWasTaken); Value++; } finally { if (__lockWasTaken) { System.Threading.Monitor.Exit(lockObject); } }
The lock syntax saves us a lot of typing, similar to other language features like foreach. We also get exception safety out of its finally block.
Finally, we add this to the test by just adding a line to Start:
Test(sw, report, "Lock Statement", lockStatement);
Mutex
Next up is the Mutex type:
Mutex mutex = new Mutex(); void mutexWaitOne() { for (int i = 0; i < reps; ++i) { mutex.WaitOne(); Value++; mutex.ReleaseMutex(); } }
WaitOne blocks until the mutex is acquired, after which the thread has exclusive access to Value and is free to modify it however it likes until we call ReleaseMutex. We just do the usual Value++.
Next, we can add this to the test with another line in Start:
Test(sw, report, "Mutex", mutexWaitOne);
Interlocked
Next up is the Interlocked class and its static CompareExchange method:
void compareExchange() { for (int i = 0; i < reps; ++i) { while (true) { int init = Value; int sum = init + 1; if (Interlocked.CompareExchange(ref Value, sum, init) == init) { break; } } } }
This technique is a little tricker to implement. We write an infinite loop that tries over and over to increment Value. It comes in a few parts.
First, we fetch Value from memory and store it in a local init variable.
Second, we modify init however we need to. In this case we just add one to get sum.
Third, we call CompareExchange with three parameters:
ref Value: The memory address we want to changesum: The value we want to writeinit: The value to compare the first parameter (ref Value) to
CompareExchange reads the value at the memory address (ref Value) and compares it to the third parameter (init). If they are the same, it writes the second parameter (sum) to the memory address (ref Value). It then returns the value that was at the memory address (ref Value) when the function started. It does all of this atomically, so no changes to the value at the memory address (ref Value) will occur during these steps.
Why does this prevents corruption of Value in our case? Well, the problem with NoSync that we’re trying to avoid is a thread execution ordering like this:
Value = 100; // Initial state of the memory at Value int aValue = Value; // Thread A reads the memory at Value: 100 int bValue = Value; // Thread B reads the memory at Value: 100 aValue++; // Thread A increments the value it read to 101 bValue++; // Thread B increments the value it read to 101 Value = aValue; // Thread A writes the new value (101) to the memory at Value Value = bValue; // Thread B writes the new value (101) to the memory at Value Value == 101; // Incorrect! Should be 102, but is 101
CompareExchange inserts a check to make sure the memory at Value is still the value it started with (100) before writing the updated value (aValue or bValue) to the memory at Value. The same thread execution ordering would look like this:
Value = 100; // Initial state of the memory at Value int aValue = Value; // Thread A reads the memory at Value: 100 int bValue = Value; // Thread B reads the memory at Value: 100 int aNewValue = aValue + 1; // Thread A increments the value it read to 101 int bNewValue = bValue + 1; // Thread B increments the value it read to 101 // If the memory at Value is unchanged, which is TRUE if (Value == aValue) { // Thread A writes the new value (101) to the memory at Value Value = aNewValue; } // If the memory at Value is unchanged, which is FALSE if (Value == bValue) { // Thread B writes the new value (101) to the memory at Value // This is NOT executed Value = bNewValue; } else { int bValue = Value; // Thread B reads the memory at Value: 101 int bNewValue = bValue + 1; // Thread B increments the value it read to 102 // If the memory at Value is unchanged, which is TRUE if (Value == bValue) { // Thread B writes the new value (102) to the memory at Value Value = bNewValue; } } Value == 102; // Correct! Thread B wrote 102 after retrying.
The above pseudo-code shows the infinite loop broken down into just the if and else cases that would execute in this hypothetical thread execution ordering.
The critical part is that Thread B detects that Thread A changed the memory at Value and starts all over. It re-fetches the memory at Value, adds one, checks again to make sure the memory at Value is what it started with this time, and finally writes its result now that the memory hasn’t changed. The result is now correct!
Finally, let’s add this to the test with a line in Start:
Test(sw, report, "CompareExchange", compareExchange);
SpinWait
The CompareExchange approach contains a tight loop that retries over and over until successful. This means that the thread will utilize its CPU core 100% until it successfully writes to Value. If there is a lot of contention, it might be good to back off and let the OS perform a context switch so another thread can use the CPU core. To do this, we’ll introduce a SpinWait:
void compareExchangeSpinOnce() { for (int i = 0; i < reps; ++i) { SpinWait spin = new SpinWait(); while (true) { int init = Value; int sum = init + 1; if (Interlocked.CompareExchange(ref Value, sum, init) == init) { break; } spin.SpinOnce(); } } }
The only difference here is that we call SpinOnce to wait a few cycles before retrying. This gives us a better shot at successfully retrying the write to Value. It will also allow a CPU context switch if waiting too long or when running on a single-core CPU where waiting is pointless.
Let’s add this test to Start:
Test(sw, report, "CompareExchange+SpinOnce", compareExchangeSpinOnce);
Running the Test
With all of our test functions written, let’s check out the final test script:
using System.Diagnostics; using System.Text; using System.Threading; using UnityEngine; class TestScript : MonoBehaviour { volatile int Value; readonly object lockObject = new object(); Mutex mutex = new Mutex(); const int reps = 1000000; void Start() { StringBuilder report = new StringBuilder(4096); report.AppendLine("Test,IsCorrect,One Thread Ticks,Two Thread Ticks"); Stopwatch sw = Stopwatch.StartNew(); Test(sw, report, "No Sync", NoSync); Test(sw, report, "Lock Statement", lockStatement); Test(sw, report, "Mutex", mutexWaitOne); Test(sw, report, "CompareExchange", compareExchange); Test(sw, report, "CompareExchange+SpinOnce", compareExchangeSpinOnce); print(report); } void Test(Stopwatch sw, StringBuilder report, string label, ThreadStart t) { Thread threadA = new Thread(t); Value = 0; sw.Restart(); threadA.Start(); threadA.Join(); long oneThreadTicks = sw.ElapsedTicks; Thread threadB = new Thread(t); Thread threadC = new Thread(t); Value = 0; sw.Restart(); threadB.Start(); threadC.Start(); threadB.Join(); threadC.Join(); long twoThreadTicks = sw.ElapsedTicks; report .Append(label).Append(',') .Append(Value == reps*2).Append(',') .Append(oneThreadTicks).Append(',') .Append(twoThreadTicks).Append('n'); } void NoSync() { for (int i = 0; i < reps; ++i) { Value++; } } void lockStatement() { for (int i = 0; i < reps; ++i) { lock (lockObject) { Value++; } } } void mutexWaitOne() { for (int i = 0; i < reps; ++i) { mutex.WaitOne(); Value++; mutex.ReleaseMutex(); } } void compareExchange() { for (int i = 0; i < reps; ++i) { while (true) { int init = Value; int sum = init + 1; if (Interlocked.CompareExchange(ref Value, sum, init) == init) { break; } } } } void compareExchangeSpinOnce() { for (int i = 0; i < reps; ++i) { SpinWait spin = new SpinWait(); while (true) { int init = Value; int sum = init + 1; if (Interlocked.CompareExchange(ref Value, sum, init) == init) { break; } spin.SpinOnce(); } } } }
I ran the test in this environment:
- 2.7 Ghz Intel Core i7-6820HQ
- macOS 10.15.4
- Unity 2019.3.9f1
- Burst package 1.2.3
- macOS Standalone
- .NET 4.x scripting runtime version and API compatibility level
- IL2CPP
- Non-development
- 640×480, Fastest, Windowed
And here are the results I got:
| Test | IsCorrect | One Thread Ticks | Two Thread Ticks |
|---|---|---|---|
| No Sync | False | 385315 | 668500 |
| Lock Statement | True | 1846390 | 8938287 |
| Mutex | True | 2719061 | 14309562 |
| CompareExchange | True | 401456 | 1462565 |
| CompareExchange+SpinOnce | True | 402419 | 802026 |
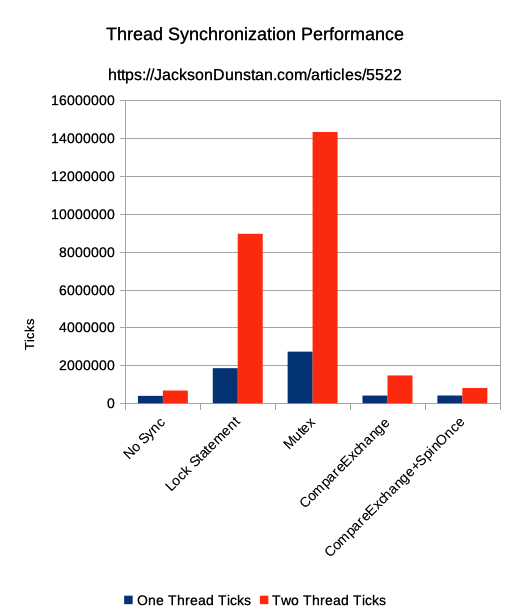
Not surprisingly, the baseline NoSync function was the fastest regardless of the number of threads being run as it performs no synchronization whatsoever. Also not surprisingly, it produces an incorrect result for Value. Even in a small test such as this, it shows the need for synchronization of some kind.
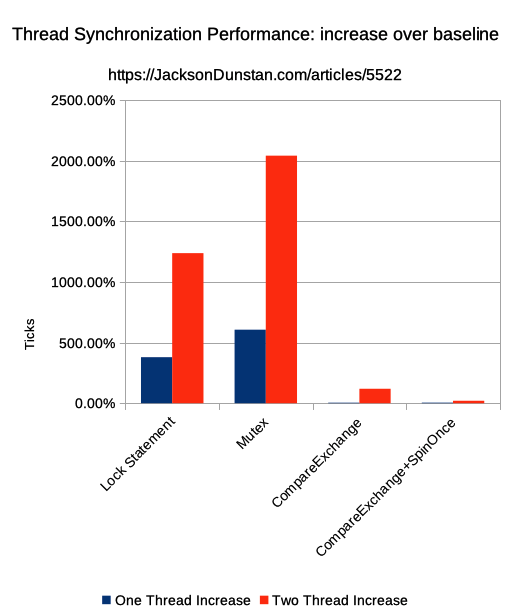
lock statements were hugely more expensive compared to the baseline. The time taken was over 4x for one thread (i.e. no contention) and over 12x for two threads. NoSync increased 1.73x when adding the second thread, but lock statements increased 4.84x. That’s the cost they paid to synchronize with some actual contention.
Mutex was even slower: over 7x more time than NoSync for one thread and over 20x more time for two threads. The jump from one thread to two was 5.26x, even more of a penalty than with lock statements.
CompareExchange was much quicker. With one thread, it took only 4% more time than NoSync. Two threads took 2.19x more time though, which is marginally higher than 1.73x from NoSync. The increase from one thread to two was 3.6x, the smallest so far.
CompareExchange+SpinOnce took only slightly more time with only one thread, but still about 4% longer than NoSync. The two thread time was much reduced compared to just CompareExchange: only 1.2x longer than NoSync. The time increase when going to two threads was only 2x, less than half the second-best (lock statements) and nearly the 1.73x that NoSync scored.
Concusion
Synchronization options are many and varied. They each come with their own complexity, safety, and performance characteristics. Which is best? No one performance test, including this one, can say definitively. The amount of work being done will surely vary from just an increment and affect things like the cost of retrying with CompareExchange. The data being accessed will likewise vary from just a single int. Exception safety may be needed, but is only tested here with lock statements. The usability of each is important too as thread synchronization is notoriously difficult and often the source of bugs.
Still, this test shows that CompareExchange with a SpinLock has the potential for great performance. It’s surely worth investigating along with the other options. The decision will ultimately need to be on a case-by-case basis, but knowing these various techniques will inform that decision. Knowing more options means there’s more chance that the best solution will be found. Speaking of more options, do you have any to share? If so, let me know in the comments!
#1 by NRett on June 2nd, 2020 ·
Does Burst package version even matter here? I thought Burst only applies to Unity Jobs, not normal C# threads (which is very unfortunate).
#2 by jackson on June 2nd, 2020 ·
No, it won’t apply since Burst wasn’t part of this test.
#3 by KornFlaks on November 11th, 2021 ·
I’ve been using extensive amounts of Interlocked in Burst to avoid having to maintain rotating read-write concurrent NativeContainers and yea, I’ve replicated these results with Interlocked Exchange.
Real shame Burst does not support spinlock (yet). Still, interlocked just existing is really nice and opens up a lot of opportunity with multithreading as I can interlocked increment values located on a single entity from multiple threads.
Burst also supports the MemoryBarrier method of System.Threading.Thread and the non-generic variants of Read and Write provided by System.Threading.Volatile but I’ve largely not found any use for them yet.
#4 by em on February 2nd, 2022 ·
Interlocked.Increment fastest of the above?