Can Fixed-Point Improve Performance?
Fixed-point types save memory compared to floating-point types, but can they also improve performance? Today’s article finds out!
Float vs. Fixed
It can seem counter-intuitive that fixed-point would be able to improve performance compared to floating-point. After all, floating-point numbers are directly supported by the CPU via a floating-point unit. This has been the case for decades and FPUs are highly optimized at this point.
It’s worth noting that floating-point and fixed-point are both approximations of real numbers, but they’re not equivalent to each other. For example, fixed-point formats like we saw last time often have no concept of NaN or infinity and they have very strict and limited ranges and precision. Not having to be as generalized or robust usually offers performance advantages.
All this said, the main reason a fixed-point number could improve performance is that it can take up much less space than a floating-point number. While size and speed are often considered orthogonal, they often have a very real overlap. To see why, let’s talk about what limits the performance of code.
Limits
Say the code is calculating the n-th digit of Ï€. There’s basically no I/O involved in this as no memory needs to be read or written. So memory could run at 1 byte-per-second or 1 terabyte-per-second and it would make no difference to the speed of the code. But if the CPU runs at 3 MHz or 3 GHz, the performance will vary a lot! The code is bound by the CPU’s ability to execute instructions so we call it CPU-bound.
Now imagine some code that loops over an array and computes the sum of its elements. The CPU work involved is negligible since it only needs to add two numbers together for each element in the array. Increasing or decreasing the CPU’s ability to add numbers won’t have much of an effect on how fast the code runs because adding is such a small part of what it does. The much bigger part is that it reads all the elements of the array from RAM. The speed of the code depends on the speed of RAM I/O, so we call it I/O-bound.
Note that we can generalize these two types of bounds from just these examples. A CPU might not be the processor in question, so we might be GPU-bound for graphics or bound by some esoteric processor for hardware-accelerated machine learning. Likewise, RAM might not be what we’re performing I/O on, so we might be bound by a hard drive, SSD, or network connection. Regardless, we’ll just use CPU-bound and I/O-bound in this article.
Test
If we’re trying to increase the performance of code that’s CPU-bound, switching from floating-point to fixed-point will likely decrease the performance instead. Executing more and slower integer instructions instead of using a single floating-point instruction will further tax the CPU, which is already overloaded. So we won’t test CPU-bound code today because fixed-point would probably be a poor choice. Instead, we’ll test some I/O-bound code that does just what we talked about above: sum an array of values.
The first version of the code will sum a NativeArray<float> and the second version will sum a NativeArray<fixed8_8>. The float version must perform twice as much I/O as the fixed8_8 version since each element takes up four bytes intead of only two. The fixed8_8 version must perform additional CPU instructions to convert to float, but in theory this won’t matter because the code is I/O bound and therefore the CPU is sitting idle anyhow while it waits for more values to arrive from RAM.
Here’s the test source code:
using System.Diagnostics; using System.Text; using Unity.Burst; using Unity.Collections; using Unity.Jobs; using UnityEngine; [BurstCompile(CompileSynchronously = true)] struct FloatJob : IJob { public NativeArray<float> Array; public NativeArray<float> Sum; public void Execute() { float sum = 0; for (int i = 0; i < Array.Length; ++i) { sum += Array[i]; } Sum[0] = sum; } } [BurstCompile(CompileSynchronously = true)] struct FixedJob : IJob { public NativeArray<fixed8_8> Array; public NativeArray<float> Sum; public void Execute() { float sum = 0; for (int i = 0; i < Array.Length; ++i) { sum += Array[i]; } Sum[0] = sum; } } class TestScript : MonoBehaviour { void Start() { const int len = 10000000; const Allocator allocator = Allocator.TempJob; var sw = new Stopwatch(); var floatTicks = 0L; var fixedTicks = 0L; using (var sum = new NativeArray<float>(1, allocator)) { using (var floatArray = new NativeArray<float>(len, allocator)) { using (var fixedArray = new NativeArray<fixed8_8>(len, allocator)) { var floatJob = new FloatJob { Array = floatArray, Sum = sum }; var fixedJob = new FixedJob { Array = fixedArray, Sum = sum }; // Warmup floatJob.Run(); fixedJob.Run(); sw.Restart(); floatJob.Run(); floatTicks += sw.ElapsedTicks; sw.Restart(); fixedJob.Run(); fixedTicks += sw.ElapsedTicks; } } } var report = new StringBuilder(10*1024); report.Append("Type,Ticksn"); report.Append("float,"); report.Append(floatTicks); report.Append('n'); report.Append("fixed8_8,"); report.Append(fixedTicks); report.Append('n'); print(report.ToString()); } }
Here’s the output from Burst Inspector showing the assembly that these jobs were compiled to:
; float mov rax, qword ptr [rdi + 56] movss xmm0, dword ptr [rax] movsxd rcx, dword ptr [rdi + 8] test rcx, rcx jle .LBB0_8 mov r8, qword ptr [rdi] cmp ecx, 8 jae .LBB0_3 xor edx, edx jmp .LBB0_6 .LBB0_3: mov rdx, rcx and rdx, -8 xorps xmm1, xmm1 blendps xmm0, xmm1, 14 lea rdi, [r8 + 16] mov rsi, rdx .p2align 4, 0x90 .LBB0_4: movups xmm2, xmmword ptr [rdi - 16] addps xmm0, xmm2 movups xmm2, xmmword ptr [rdi] addps xmm1, xmm2 add rdi, 32 add rsi, -8 jne .LBB0_4 addps xmm1, xmm0 movaps xmm0, xmm1 movhlps xmm0, xmm0 addps xmm0, xmm1 haddps xmm0, xmm0 cmp rdx, rcx je .LBB0_8 .LBB0_6: sub rcx, rdx lea rdx, [r8 + 4*rdx] .p2align 4, 0x90 .LBB0_7: addss xmm0, dword ptr [rdx] add rdx, 4 dec rcx jne .LBB0_7 .LBB0_8: movss dword ptr [rax], xmm0 ret ; fixed8_8 mov rax, qword ptr [rdi + 56] movss xmm0, dword ptr [rax] movsxd rcx, dword ptr [rdi + 8] test rcx, rcx jle .LBB0_8 mov r8, qword ptr [rdi] cmp ecx, 8 jae .LBB0_3 xor edx, edx jmp .LBB0_6 .LBB0_3: mov rdx, rcx and rdx, -8 xorps xmm1, xmm1 blendps xmm0, xmm1, 14 lea rdi, [r8 + 8] movabs rsi, offset .LCPI0_0 movaps xmm2, xmmword ptr [rsi] mov rsi, rdx .p2align 4, 0x90 .LBB0_4: pmovsxwd xmm3, qword ptr [rdi - 8] cvtdq2ps xmm3, xmm3 pmovsxwd xmm4, qword ptr [rdi] cvtdq2ps xmm4, xmm4 mulps xmm3, xmm2 addps xmm0, xmm3 mulps xmm4, xmm2 addps xmm1, xmm4 add rdi, 16 add rsi, -8 jne .LBB0_4 addps xmm1, xmm0 movaps xmm0, xmm1 movhlps xmm0, xmm0 addps xmm0, xmm1 haddps xmm0, xmm0 cmp rdx, rcx je .LBB0_8 .LBB0_6: sub rcx, rdx lea rdx, [r8 + 2*rdx] movabs rsi, offset .LCPI0_1 movss xmm1, dword ptr [rsi] .p2align 4, 0x90 .LBB0_7: movsx esi, word ptr [rdx] xorps xmm2, xmm2 cvtsi2ss xmm2, esi mulss xmm2, xmm1 addss xmm0, xmm2 add rdx, 2 dec rcx jne .LBB0_7 .LBB0_8: movss dword ptr [rax], xmm0 ret
Notice that the fixed-point version does involve quite a few more instructions than the floating-point version.
Results
I ran the test in this environment:
- 2.7 Ghz Intel Core i7-6820HQ
- macOS 10.14.6
- Unity 2019.2.15f1
- macOS Standalone
- .NET 4.x scripting runtime version and API compatibility level
- IL2CPP
- Non-development
- 640×480, Fastest, Windowed
And here are the results I got:
| Type | Ticks |
|---|---|
| float | 144020 |
| fixed8_8 | 126567 |
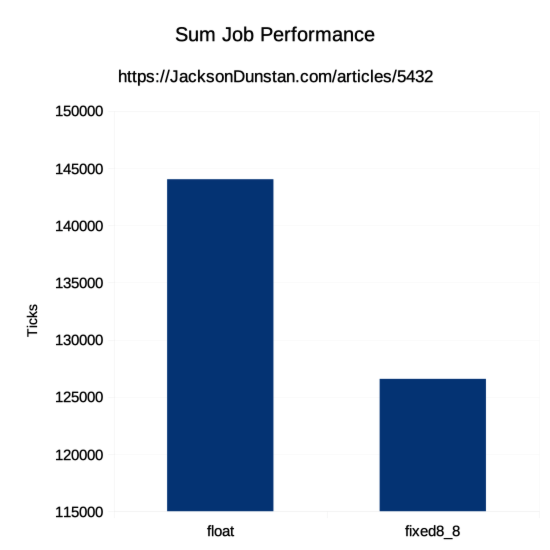
As predicted, the floating-point version takes about 14% longer to run than the fixed-point version. The extra instructions to convert from fixed-point to floating-point were more than counteracted by the I/O savings, resulting in an overall improvement.
Conclusion
Code performance is either CPU-bound or I/O-bound. When facing I/O-bound code, it can really help to reduce the total amount of data that needs to be read or written. Using fixed-point is one way to reduce these data sizes. Bit streams are another.
#1 by Art on December 10th, 2019 ·
Hi! Why don’t you make videos for Youtube ?
#2 by jackson on December 10th, 2019 ·
In-depth technical articles like these don’t really suit the video format very well.
#3 by Baggers on January 14th, 2020 ·
Really good to see a concrete example of this using the job system. Thanks for writing it