Math.Abs vs. Mathf.Abs vs. math.abs vs. Custom
A reader recently asked what the fastest way to take an absolute value was. It occurred to me that there are a lot of ways to do this in Unity! So today we’ll try them all out and see which is best.
Update: A Russian translation of this article is available.
Options
How many ways can we take the absolute value of a float? Let us count:
a = System.Math.Math.Abs(f);a = UnityEngine.Mathf.Abs(f);a = Unity.Mathematics.math.abs(f);if (f >= 0) a = f; else a = -f;a = f >= 0 ? f : -f;
That's a lot of ways! The custom options (#3 and #4) are obvious, but let's dive into the others to see what they're doing. Here's a decompiled version of Math.Abs:
[MethodImpl(4096)] public static extern float Abs(float value);
This is implemented in native code, so the C# trail ends here. Let's move on to #2 and look at Mathf.Abs:
public static float Abs(float f) { return Math.Abs(f); }
This is just a wrapper around Math.Abs! Moving on, let's see math.abs:
[MethodImpl(MethodImplOptions.AggressiveInlining)] public static float abs(float x) { return asfloat(asuint(x) & 0x7FFFFFFF); }
Apparently, this is implemented by converting the float to a uint, making the sign bit (0x7FFFFFFF is 0 followed by 31 1s) a zero, then converting back to a float. To see the conversions, let's look at asuint:
[MethodImpl(MethodImplOptions.AggressiveInlining)] public static uint asuint(float x) { return (uint)asint(x); }
This just wraps asint:
[MethodImpl(MethodImplOptions.AggressiveInlining)] public static int asint(float x) { IntFloatUnion u; u.intValue = 0; u.floatValue = x; return u.intValue; }
asint uses a union to alias the memory without changing the bits. We've seen that trick before and know that it even works with Burst. Here's how Unity implemented it:
[StructLayout(LayoutKind.Explicit)] internal struct IntFloatUnion { [FieldOffset(0)] public int intValue; [FieldOffset(0)] public float floatValue; }
This is the same approach as we've seen before: the same memory within the struct is used to hold the int and the float so its type can be changed without affecting the bits.
Now let's look at the return trip and see how the uint is changed back into a float:
[MethodImpl(MethodImplOptions.AggressiveInlining)] public static float asfloat(uint x) { return asfloat((int)x); }
Again, this just uses the int overload:
[MethodImpl(MethodImplOptions.AggressiveInlining)] public static float asfloat(int x) { IntFloatUnion u; u.floatValue = 0; u.intValue = x; return u.floatValue; }
This does the opposite of before using the same union.
Jobs
Next, let's write some Burst-compiled jobs to test out each of these approaches by taking the absolute value of one element of a NativeArray<float>:
[BurstCompile] struct SingleSystemMathAbsJob : IJob { public NativeArray<float> Values; public void Execute() { Values[0] = Math.Abs(Values[0]); } } [BurstCompile] struct SingleUnityEngineMathfAbsJob : IJob { public NativeArray<float> Values; public void Execute() { Values[0] = Mathf.Abs(Values[0]); } } [BurstCompile] struct SingleUnityMathematicsMathAbsJob : IJob { public NativeArray<float> Values; public void Execute() { Values[0] = math.abs(Values[0]); } } [BurstCompile] struct SingleIfJob : IJob { public NativeArray<float> Values; public void Execute() { float val = Values[0]; if (val >= 0) { Values[0] = val; } else { Values[0] = -val; } } } [BurstCompile] struct SingleTernaryJob : IJob { public NativeArray<float> Values; public void Execute() { float val = Values[0]; Values[0] = val >= 0 ? val : -val; } }
We'll look at the results of the performance test later on, but for now let's take a deeper look and see the assembly code that Burst compiles each of these jobs to. This will show us what the CPU will actually run and reveal some details hidden by the native code implementation of Math.Abs.
First, here is the assembly for both Math.Abs and Mathf.Abs:
mov rax, qword ptr [rdi] movss xmm0, dword ptr [rax] movabs rcx, offset .LCPI0_0 andps xmm0, xmmword ptr [rcx] movss dword ptr [rax], xmm0 ret
The key line here is andps which is performing the & 0x7FFFFFFF we saw in math.abs to clear the most-significant bit.
Now let's look at the Burst output for math.abs:
mov rax, qword ptr [rdi] movss xmm0, dword ptr [rax] movabs rcx, offset .LCPI0_0 andps xmm0, xmmword ptr [rcx] movss dword ptr [rax], xmm0 ret
As expected, this also uses andps. In fact, it's identical to the output for Math.Abs and Mathf.Abs!
Here's the custom version based on if:
mov rax, qword ptr [rdi] movss xmm0, dword ptr [rax] xorps xmm1, xmm1 ucomiss xmm1, xmm0 jbe .LBB0_2 movabs rcx, offset .LCPI0_0 xorps xmm0, xmmword ptr [rcx] movss dword ptr [rax], xmm0 .LBB0_2: ret
This version introduces a branch: jbe. This skips writing anything to the array when the value is positive. That's an improvement because there's less memory to write but the branch may result in misprediction that inefficiently uses the CPU.
Finally, here's the custom version based on the ternary operator:
mov rax, qword ptr [rdi] movss xmm0, dword ptr [rax] movabs rcx, offset .LCPI0_0 andps xmm0, xmmword ptr [rcx] movss dword ptr [rax], xmm0 ret
Strangely, this version does not include a branch like in the if-based version. Instead, it's identical to the output for Math.Abs, Mathf.Abs, and math.abs! Somehow Burst was able to detect and radically transform the code in this version, but not with if.
Performance
Now let's put all of these approaches to a performance test to see which is fastest. We'll do this by taking the absolute value of every element of a NativeArray<float> containing random values:
using System; using System.Diagnostics; using Unity.Burst; using Unity.Collections; using Unity.Jobs; using Unity.Mathematics; using UnityEngine; [BurstCompile] struct SystemMathAbsJob : IJob { public NativeArray<float> Values; public void Execute() { for (int i = 0; i < Values.Length; ++i) { Values[i] = Math.Abs(Values[i]); } } } [BurstCompile] struct UnityEngineMathfAbsJob : IJob { public NativeArray<float> Values; public void Execute() { for (int i = 0; i < Values.Length; ++i) { Values[i] = Mathf.Abs(Values[i]); } } } [BurstCompile] struct UnityMathematicsMathAbsJob : IJob { public NativeArray<float> Values; public void Execute() { for (int i = 0; i < Values.Length; ++i) { Values[i] = math.abs(Values[i]); } } } [BurstCompile] struct IfJob : IJob { public NativeArray<float> Values; public void Execute() { for (int i = 0; i < Values.Length; ++i) { float val = Values[i]; if (val >= 0) { Values[i] = val; } else { Values[i] = -val; } } } } [BurstCompile] struct TernaryJob : IJob { public NativeArray<float> Values; public void Execute() { for (int i = 0; i < Values.Length; ++i) { float val = Values[i]; Values[i] = val >= 0 ? val : -val; } } } class TestScript : MonoBehaviour { void Start() { NativeArray<float> values = new NativeArray<float>( 100000, Allocator.TempJob); for (int i = 0; i < values.Length; ++i) { values[i] = UnityEngine.Random.Range(float.MinValue, float.MaxValue); } SystemMathAbsJob systemMathAbsJob = new SystemMathAbsJob { Values = values }; UnityEngineMathfAbsJob unityEngineMathfAbsJob = new UnityEngineMathfAbsJob { Values = values }; UnityMathematicsMathAbsJob unityMathematicsMathAbsJob = new UnityMathematicsMathAbsJob { Values = values }; IfJob ifJob = new IfJob { Values = values }; TernaryJob ternaryJob = new TernaryJob { Values = values }; // Warm up the job system systemMathAbsJob.Run(); unityEngineMathfAbsJob.Run(); unityMathematicsMathAbsJob.Run(); ifJob.Run(); ternaryJob.Run(); Stopwatch sw = Stopwatch.StartNew(); systemMathAbsJob.Run(); long systemMathAbsTicks = sw.ElapsedTicks; sw.Restart(); unityEngineMathfAbsJob.Run(); long unityEngineMathfAbsTicks = sw.ElapsedTicks; sw.Restart(); unityMathematicsMathAbsJob.Run(); long unityMathematicsMathAbsTicks = sw.ElapsedTicks; sw.Restart(); ifJob.Run(); long ifTicks = sw.ElapsedTicks; sw.Restart(); ternaryJob.Run(); long ternaryTicks = sw.ElapsedTicks; values.Dispose(); print( "Function,Ticksn" + "System.Math.Abs," + systemMathAbsTicks + "n" + "UnityEngine.Mathf.Abs," + unityEngineMathfAbsTicks + "n" + "Unity.Mathematics.Math.Abs," + unityMathematicsMathAbsTicks + "n" + "If," + ifTicks + "n" + "Ternary," + ternaryTicks ); } }
Here's the test machine I ran this on:
- 2.7 Ghz Intel Core i7-6820HQ
- macOS 10.14.6
- Unity 2018.4.3f1
- macOS Standalone
- .NET 4.x scripting runtime version and API compatibility level
- IL2CPP
- Non-development
- 640×480, Fastest, Windowed
| Function | Ticks |
|---|---|
| System.Math.Abs | 253 |
| UnityEngine.Mathf.Abs | 198 |
| Unity.Mathematics.Math.Abs | 195 |
| If | 517 |
| Ternary | 1447 |
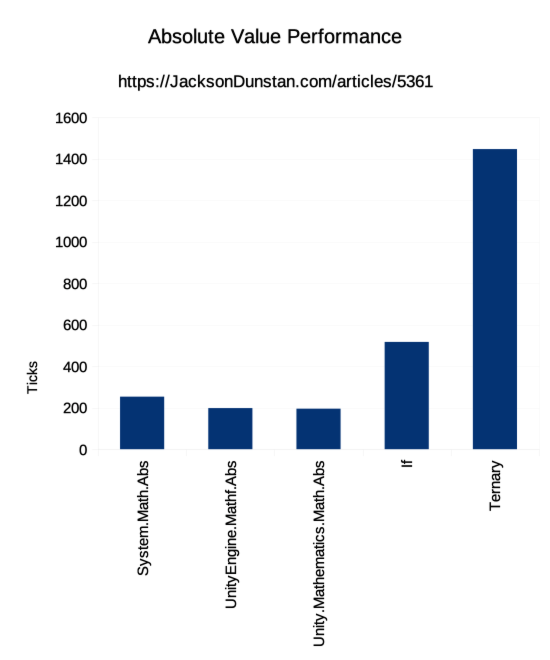
The performance is unexpectedly varied! We previously saw that four out of five versions had the exact same assembly output. Yet in the results we only see Math.Abs, Mathf.Abs, and math.Abs with about the same performance. The ternary-based custom version should have performed the same, but didn't. In fact, the ternary version performed over 10x worse!
To find out what's going on, let's look at the assembly code in Burst Inspector for these jobs to see if the added loop impacted the output.
Math.Abs, Mathf.Abs, and math.abs:
movsxd rax, dword ptr [rdi + 8] test rax, rax jle .LBB0_8 mov rcx, qword ptr [rdi] cmp eax, 8 jae .LBB0_3 xor edx, edx jmp .LBB0_6 .LBB0_3: mov rdx, rax and rdx, -8 lea rsi, [rcx + 16] movabs rdi, offset .LCPI0_0 movaps xmm0, xmmword ptr [rdi] mov rdi, rdx .p2align 4, 0x90 .LBB0_4: movups xmm1, xmmword ptr [rsi - 16] movups xmm2, xmmword ptr [rsi] andps xmm1, xmm0 andps xmm2, xmm0 movups xmmword ptr [rsi - 16], xmm1 movups xmmword ptr [rsi], xmm2 add rsi, 32 add rdi, -8 jne .LBB0_4 cmp rdx, rax je .LBB0_8 .LBB0_6: sub rax, rdx lea rcx, [rcx + 4*rdx] movabs rdx, offset .LCPI0_0 movaps xmm0, xmmword ptr [rdx] .p2align 4, 0x90 .LBB0_7: movss xmm1, dword ptr [rcx] andps xmm1, xmm0 movss dword ptr [rcx], xmm1 add rcx, 4 dec rax jne .LBB0_7 .LBB0_8: ret
if:
movsxd rax, dword ptr [rdi + 8] test rax, rax jle .LBB0_26 mov r8, qword ptr [rdi] cmp eax, 8 jae .LBB0_3 xor edx, edx jmp .LBB0_22 .LBB0_3: mov rdx, rax and rdx, -8 xorps xmm0, xmm0 movabs rsi, offset .LCPI0_0 movaps xmm1, xmmword ptr [rsi] mov rsi, r8 mov rdi, rdx .p2align 4, 0x90 .LBB0_4: movups xmm3, xmmword ptr [rsi] movups xmm2, xmmword ptr [rsi + 16] movaps xmm4, xmm3 cmpltps xmm4, xmm0 pextrb ecx, xmm4, 0 test cl, 1 jne .LBB0_5 pextrb ecx, xmm4, 4 test cl, 1 jne .LBB0_7 .LBB0_8: pextrb ecx, xmm4, 8 test cl, 1 jne .LBB0_9 .LBB0_10: pextrb ecx, xmm4, 12 test cl, 1 je .LBB0_12 .LBB0_11: shufps xmm3, xmm3, 231 xorps xmm3, xmm1 movss dword ptr [rsi + 12], xmm3 .LBB0_12: movaps xmm3, xmm2 cmpltps xmm3, xmm0 pextrb ecx, xmm3, 0 test cl, 1 jne .LBB0_13 pextrb ecx, xmm3, 4 test cl, 1 jne .LBB0_15 .LBB0_16: pextrb ecx, xmm3, 8 test cl, 1 jne .LBB0_17 .LBB0_18: pextrb ecx, xmm3, 12 test cl, 1 jne .LBB0_19 .LBB0_20: add rsi, 32 add rdi, -8 jne .LBB0_4 jmp .LBB0_21 .p2align 4, 0x90 .LBB0_5: movaps xmm5, xmm3 xorps xmm5, xmm1 movss dword ptr [rsi], xmm5 pextrb ecx, xmm4, 4 test cl, 1 je .LBB0_8 .LBB0_7: movshdup xmm5, xmm3 xorps xmm5, xmm1 movss dword ptr [rsi + 4], xmm5 pextrb ecx, xmm4, 8 test cl, 1 je .LBB0_10 .LBB0_9: movaps xmm5, xmm3 movhlps xmm5, xmm5 xorps xmm5, xmm1 movss dword ptr [rsi + 8], xmm5 pextrb ecx, xmm4, 12 test cl, 1 jne .LBB0_11 jmp .LBB0_12 .p2align 4, 0x90 .LBB0_13: movaps xmm4, xmm2 xorps xmm4, xmm1 movss dword ptr [rsi + 16], xmm4 pextrb ecx, xmm3, 4 test cl, 1 je .LBB0_16 .LBB0_15: movshdup xmm4, xmm2 xorps xmm4, xmm1 movss dword ptr [rsi + 20], xmm4 pextrb ecx, xmm3, 8 test cl, 1 je .LBB0_18 .LBB0_17: movaps xmm4, xmm2 movhlps xmm4, xmm4 xorps xmm4, xmm1 movss dword ptr [rsi + 24], xmm4 pextrb ecx, xmm3, 12 test cl, 1 je .LBB0_20 .LBB0_19: shufps xmm2, xmm2, 231 xorps xmm2, xmm1 movss dword ptr [rsi + 28], xmm2 add rsi, 32 add rdi, -8 jne .LBB0_4 .LBB0_21: cmp rdx, rax je .LBB0_26 .LBB0_22: lea rcx, [r8 + 4*rdx] sub rax, rdx xorps xmm0, xmm0 movabs rdx, offset .LCPI0_0 movaps xmm1, xmmword ptr [rdx] .p2align 4, 0x90 .LBB0_25: movss xmm2, dword ptr [rcx] ucomiss xmm0, xmm2 jbe .LBB0_24 xorps xmm2, xmm1 movss dword ptr [rcx], xmm2 .LBB0_24: add rcx, 4 dec rax jne .LBB0_25 .LBB0_26: ret
Ternary:
xor eax, eax
movabs rcx, offset .LCPI0_0
movaps xmm0, xmmword ptr [rcx]
.p2align 4, 0x90
.LBB0_2:
mov rcx, qword ptr [rdi]
movss xmm1, dword ptr [rcx + 4*rax]
andps xmm1, xmm0
movss dword ptr [rcx + 4*rax], xmm1
inc rax
movsxd rcx, dword ptr [rdi + 8]
cmp rax, rcx
jl .LBB0_2
.LBB0_3:
retJust from a high level, we see that the if version is now substantially longer and more complex than the version for Math.Abs, Mathf.Abs, and math.abs. So it's not surprising that it's about half as fast.
The custom version based on the ternary operator, on the other hand, is by far the smallest of the three outputs. It's a simple loop that performs the mask operation. So why is it so slow? Well, it happens to be the last job to run but moving it to earlier in the test has no impact on the results. Instead, the problem is that this version performs fewer absolute value operations per loop than the others. As a result, it spends more time on the loop and potentially branch mispredictions and less time taking absolute values.
Conclusion
When performing just one operation, Burst outputs identical code regardless of whether Math.Abs, Mathf.Abs, math.abs, or a ternary operator is used. When if is used, Burst outputs a branch instruction. So in this form, all approaches are equal except the if-based approach which should be avoided.
When run in a loop, Burst produces identical machine code for the three fastest approaches: Math.Abs, Mathf.Abs, and math.abs. Using an if is about 2x slower and a ternary is about 10x slower. Both should be avoided.
Put simply, Math.Abs, Mathf.Abs, and math.abs are all the best options.
#1 by sschoener on September 2nd, 2019 ·
Thanks for the post :) As for the difference between the Ternary version and the Abs version: It is unlikely that this is due to branch mispredictions. There is only a single branch and this will *always* be taken except for the last iteration of the loop. The branch predictor will catch onto this immediately. The performance difference to me looks more like 8x than 10x — which would be neatly explained by the lack of vectorization.
My main question is why the If version is so much faster than the Ternary version. Looking at the assembly, it is doing 8 floats per iteration but then goes ahead and manually extracts the sign bit for each and every one of them and does some wild jumping that depends on the value of said sign. _That_ should give you branch mispredictions. Just as an experiment to see how bad the mispredictions affect the If-version, you could sort the input array before taking the absolute value.
#2 by sschoener on September 2nd, 2019 ·
Potential causes: fewer writes in the If version (in that case their performance should be equivalent if you pass in an array of all negative numbers) or fewer reads (it is reading the 8 floats at once).
#3 by d33ds on September 2nd, 2019 ·
Abs.olutely wowed!
#4 by Serepa on September 2nd, 2019 ·
WTF dude? How is it possible that Mathf.Abs() => Math.Abs() faster than just Math.Abs()?
#5 by jackson on September 2nd, 2019 ·
Both, and
math.abs, get compiled to the same machine code so the difference in the numbers is just testing noise. As the conclusion says, all three are the best choice so no need to worry about which you choose as long as you don’t make your own version based onifor a ternary operator.#6 by Test on September 3rd, 2019 ·
Have you tried reinterpreting somehow and just doing a branchless and to make the sign bit zero?
https://bits.stephan-brumme.com/absFloat.html
#7 by jackson on September 3rd, 2019 ·
That’s exactly what all of them compile to with the exception of the custom version based on
if. In the case ofmath.abs, even the C# is essentially reinterpreting and clearing the sign bit.