Free Performance with Unity.Mathematics
Along with Unity 2019.1 and Burst, the Unity.Mathematics package is now out of Preview. It offers alternatives to longstanding core types in Unity such as Vector3, Matrix4x4, and Quaternion. Today we’ll see how switching to these types can improve performance in Burst-compiled jobs.
The Unity.Mathematics package offers tons of types and functions. Usually all that we need to do to make use of them is to change how we spell these types and functions. Instead of Vector3 we use float3. Instead of Vector3.Dot(a, b) we use math.dot(a, b). It’s almost a search-and-replace in many cases and that’s nearly “free” in terms of cost to implement.
So now let’s look at what we can expect for making this switch. To test, we’ll write a little script that runs pairs of jobs. Each pair will cover a type like Vector3 in the UnityEngine namespace and a type like float3 in the Unity.Mathematics namespace. Each job will perform a binary operation on pairs of elements from two million-element NativeArray instances and store the result in a third NativeArray. We’ll run these jobs 100 times and report the median time taken by each job.
using System; using System.Diagnostics; using Unity.Burst; using Unity.Collections; using Unity.Jobs; using Unity.Mathematics; using UnityEngine; class TestScript : MonoBehaviour { [BurstCompile] struct UE3DVecJob : IJob { public NativeArray<Vector3> A; public NativeArray<Vector3> B; public NativeArray<Vector3> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] + B[i]; } } } [BurstCompile] struct UM3DVecJob : IJob { public NativeArray<float3> A; public NativeArray<float3> B; public NativeArray<float3> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] + B[i]; } } } [BurstCompile] struct UEMat4Job : IJob { public NativeArray<Matrix4x4> A; public NativeArray<Matrix4x4> B; public NativeArray<Matrix4x4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] * B[i]; } } } [BurstCompile] struct UMMat4Job : IJob { public NativeArray<float4x4> A; public NativeArray<float4x4> B; public NativeArray<float4x4> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] * B[i]; } } } [BurstCompile] struct UEQuatJob : IJob { public NativeArray<Quaternion> A; public NativeArray<Quaternion> B; public NativeArray<Quaternion> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = A[i] * B[i]; } } } [BurstCompile] struct UMQuatJob : IJob { public NativeArray<quaternion> A; public NativeArray<quaternion> B; public NativeArray<quaternion> C; public void Execute() { for (int i = 0; i < A.Length; ++i) { C[i] = math.mul(A[i], B[i]); } } } void Start() { const int size = 1000000; const Allocator alloc = Allocator.TempJob; NativeArray<Vector3> v3a = new NativeArray<Vector3>(size, alloc); NativeArray<Vector3> v3b = new NativeArray<Vector3>(size, alloc); NativeArray<Vector3> v3c = new NativeArray<Vector3>(size, alloc); NativeArray<float3> f3a = new NativeArray<float3>(size, alloc); NativeArray<float3> f3b = new NativeArray<float3>(size, alloc); NativeArray<float3> f3c = new NativeArray<float3>(size, alloc); NativeArray<Matrix4x4> m4a = new NativeArray<Matrix4x4>(size, alloc); NativeArray<Matrix4x4> m4b = new NativeArray<Matrix4x4>(size, alloc); NativeArray<Matrix4x4> m4c = new NativeArray<Matrix4x4>(size, alloc); NativeArray<float4x4> f4a = new NativeArray<float4x4>(size, alloc); NativeArray<float4x4> f4b = new NativeArray<float4x4>(size, alloc); NativeArray<float4x4> f4c = new NativeArray<float4x4>(size, alloc); NativeArray<Quaternion> ueqa = new NativeArray<Quaternion>(size, alloc); NativeArray<Quaternion> ueqb = new NativeArray<Quaternion>(size, alloc); NativeArray<Quaternion> ueqc = new NativeArray<Quaternion>(size, alloc); NativeArray<quaternion> umqa = new NativeArray<quaternion>(size, alloc); NativeArray<quaternion> umqb = new NativeArray<quaternion>(size, alloc); NativeArray<quaternion> umqc = new NativeArray<quaternion>(size, alloc); for (int i = 0; i < size; ++i) { v3a[i] = Vector3.zero; v3b[i] = Vector3.zero; v3c[i] = Vector3.zero; f3a[i] = float3.zero; f3b[i] = float3.zero; f3c[i] = float3.zero; m4a[i] = Matrix4x4.identity; m4b[i] = Matrix4x4.identity; m4c[i] = Matrix4x4.identity; f4a[i] = float4x4.identity; f4b[i] = float4x4.identity; f4c[i] = float4x4.identity; ueqa[i] = Quaternion.identity; ueqb[i] = Quaternion.identity; ueqc[i] = Quaternion.identity; umqa[i] = quaternion.identity; umqb[i] = quaternion.identity; umqc[i] = quaternion.identity; } UE3DVecJob v3j = new UE3DVecJob { A = v3a, B = v3b, C = v3c }; UM3DVecJob f3j = new UM3DVecJob { A = f3a, B = f3b, C = f3c }; UEMat4Job m4j = new UEMat4Job { A = m4a, B = m4b, C = m4c }; UMMat4Job f4j = new UMMat4Job { A = f4a, B = f4b, C = f4c }; UEQuatJob ueqj = new UEQuatJob { A = ueqa, B = ueqb, C = ueqc }; UMQuatJob umqj = new UMQuatJob { A = umqa, B = umqb, C = umqc }; const int reps = 100; long[] v3t = new long[reps]; long[] f3t = new long[reps]; long[] m4t = new long[reps]; long[] f4t = new long[reps]; long[] ueqt = new long[reps]; long[] umqt = new long[reps]; Stopwatch sw = new Stopwatch(); for (int i = 0; i < reps; ++i) { sw.Restart(); v3j.Run(); v3t[i] = sw.ElapsedTicks; sw.Restart(); f3j.Run(); f3t[i] = sw.ElapsedTicks; sw.Restart(); m4j.Run(); m4t[i] = sw.ElapsedTicks; sw.Restart(); f4j.Run(); f4t[i] = sw.ElapsedTicks; sw.Restart(); ueqj.Run(); ueqt[i] = sw.ElapsedTicks; sw.Restart(); umqj.Run(); umqt[i] = sw.ElapsedTicks; } print( "Job,UnityEngine Time,Unity.Mathematics Timen" + "3D Vector," + Median(v3t) + "," + Median(f3t) + "n" + "4x4 Matrix," + Median(m4t) + "," + Median(f4t) + "n" + "Quaternion," + Median(ueqt) + "," + Median(umqt)); v3a.Dispose(); v3b.Dispose(); v3c.Dispose(); f3a.Dispose(); f3b.Dispose(); f3c.Dispose(); m4a.Dispose(); m4b.Dispose(); m4c.Dispose(); f4a.Dispose(); f4b.Dispose(); f4c.Dispose(); ueqa.Dispose(); ueqb.Dispose(); ueqc.Dispose(); umqa.Dispose(); umqb.Dispose(); umqc.Dispose(); Application.Quit(); } static long Median(long[] values) { Array.Sort(values); return values[values.Length / 2]; } }
I ran the test using this environment:
- 2.7 Ghz Intel Core i7-6820HQ
- macOS 10.14.4
- Unity 2019.1.0f2
- macOS Standalone
- .NET 4.x scripting runtime version and API compatibility level
- IL2CPP
- Non-development
- 640×480, Fastest, Windowed
And here are the results I got:
| Job | UnityEngine Time | Unity.Mathematics Time |
|---|---|---|
| 3D Vector | 24550 | 22690 |
| 4×4 Matrix | 122260 | 112450 |
| Quaternion | 39730 | 33150 |
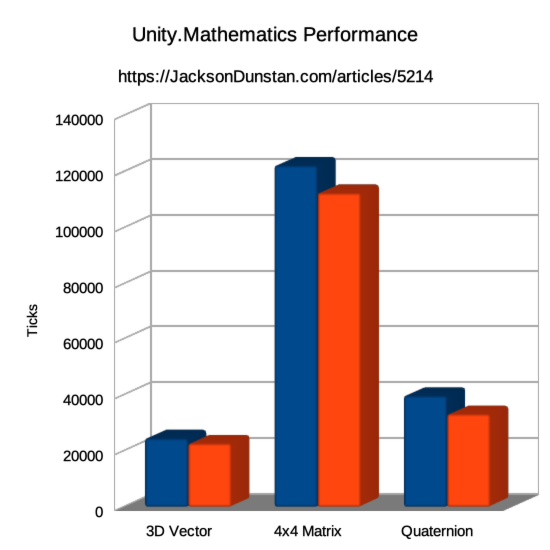
For these particular types and operations, we’re saving about 8-17% of the CPU time by switching to Unity.Mathematics. That’s not as much as switching to Burst, but it’s quite a lot for the amount of effort required!
To see exactly why the performance has improved, we can use the Burst Inspector to see the code it generated:
Jobs > Burst > Open Inspector...- Click
TestScript.BurstJobon the left - Check
Enhanced Disassemblyon the right - Uncheck
Safety Checkson the right - Click
Refresh Disassemblyon the right
For example, here is the assembly Burst generated for the 3D Vector types: Vector3 and float3.
; Vector3 movss xmm0, dword ptr [rdx + rdi - 8] movss xmm1, dword ptr [rdx + rdi - 4] movss xmm2, dword ptr [rdx + rdi] addss xmm0, dword ptr [rcx + rdi - 8] addss xmm1, dword ptr [rcx + rdi - 4] addss xmm2, dword ptr [rcx + rdi] movss dword ptr [rsi + rdi - 8], xmm0 movss dword ptr [rsi + rdi - 4], xmm1 movss dword ptr [rsi + rdi], xmm2 ; float3 movsd xmm0, qword ptr [rcx + rdi] insertps xmm0, dword ptr [rcx + rdi + 8], 32 movsd xmm1, qword ptr [rdx + rdi] insertps xmm1, dword ptr [rdx + rdi + 8], 32 addps xmm1, xmm0 movss dword ptr [rsi + rdi], xmm1 extractps dword ptr [rsi + rdi + 4], xmm1, 1 extractps dword ptr [rsi + rdi + 8], xmm1, 2
Burst is generating SIMD instructions for both, but the float3 version uses only 8 instructions where the Vector3 version uses 9 and one of them (addps xmm1, xmm0) doesn't involve memory at all. A simple instruction count isn't definitive, but it's a good estimate that's roughly in line with the 8% savings we saw in the test.
The other jobs' assembly is much longer so I'll omit them here, but suffice to say that they too have somewhat better assembly code output.
In conclusion, consider switching from the types and functions in the UnityEngine namespace to the types and functions in the Unity.Mathematics package for a "free" performance boost. This isn't always possible, such as when using much of the Unity API, but for newer code built on the job system it's an rare easy win.
#1 by Sebastian Schoener on April 29th, 2019 ·
Thanks for the benchmarks, always interesting :) I would be very interested in seeing how the performance changes when going from float3 to float4 (see the notes on the supported data types here: https://docs.unity3d.com/Packages/com.unity.burst@1.0/manual/index.html#supported-net-types ) and what differences there are in the generated output.
#2 by jackson on April 29th, 2019 ·
There are a lot more types and functions in Unity.Mathematics than we’ve had before, so there’s a lot more to cover. For this article, I just kept it to an apples-to-apples comparison.
#3 by Mahdi Jeddi on April 29th, 2019 ·
I guess even for Unity API usage we could just use the unsafe memory copy?
#4 by jackson on April 29th, 2019 ·
Yes, you’ll need to convert between types somehow to use a lot of the Unity APIs. An unsafe memory copy is fine, as are safe copies like this: