JSON Is Incredibly Bloated
In previous articles I’ve compared the performance of various JSON libraries. Unity’s built-in JsonUtility usually comes out on top, but that conclusion loses sight of the bigger picture. JsonUtility is only really fast when you compare it to other JSON libraries. Compared to non-JSON alternatives, it’s ludicrously slow and oversized. Today’s article compares JSON to an alternative format to highlight just how bloated JSON is.
First of all, JSON is great for many purposes. It’s simple, human-readable, and widely used. You might not even have a choice if you need to communicate with some web service beyond your control. That aside, let’s analyze it from two perspectives today: speed and size.
Instead of JSON, consider a custom binary format for the SaveGame type from previous JSON articles:
[Serializable] public struct SaveGame { public string Name; public int HighScore; }
Now consider this custom binary format. On the left is the size in bytes and on the right is a note for how they’re used:
4 - Required size of a buffer to load this SaveGame 2+N*2 - UTF-16 characters of a Name that's N long. Ends in NUL terminator. 4 - High score
This format requires 10 bytes plus two more for every character in the Name field. Now compare to JSON:
{"Name":"","HighScore":1}JSON requires 24 bytes plus the Name characters and characters for the HighScore. The name will vary depending on the character encoding of the JSON document. The high score will vary depending on the integer value, but it could be up to 10 bytes: -1000000000.
It’s possible to tune the custom binary format for even smaller size, if desired. The required size could be dropped and the Name could be encoded with UTF-8 if a lot of ASCII is expected. I’ve skipped those steps for simplicity in this article since today’s purpose isn’t to design a competitor to JSON or make a format usable for any real life application.
Now for speed. Serializing and deserializing a SaveGame is a simple matter of writing and reading its fields. This can be done easily by marching a pointer through a buffer to read from or write to. Unsafe code is required, but that’s not an issue for common platforms like Android and iOS. Here is a static class with simple Serialize and Deserialize functions you can call:
public unsafe static class SaveGameSerializer { public static byte[] Serialize(ref SaveGame saveGame) { var size = 8 // Required size + HighScore + saveGame.Name.Length * 2 + sizeof(char); // Name var bytes = new byte[size]; fixed (byte* pInto = bytes) { // Required size var pDest = pInto; *((int*)pDest) = size; pDest += sizeof(int); // Name fixed (char* pName = saveGame.Name) { while (*pName != '\0') { *((char*)pDest) = *pName; pDest += sizeof(char); pName++; } *((char*)pDest) = '\0'; pDest += sizeof(char); } // HighScore *((int*)pDest) = saveGame.HighScore; pDest += sizeof(int); } return bytes; } public static bool Deserialize(byte[] bytes, ref SaveGame into) { fixed (byte* pBytes = bytes) { // Need at least enough for required size var size = bytes.Length; if (size < sizeof(int)) { return false; } var pSrc = pBytes; // Required size var requiredSize = *((int*)pSrc); if (size < requiredSize) { return false; } pSrc += sizeof(int); // Name into.Name = new string((char*)pSrc); pSrc += 2 * into.Name.Length + sizeof(char); // HighScore into.HighScore = *((int*)pSrc); pSrc += sizeof(int); } return true; } }
Now let’s look at the script to put both methods to the test. It simply serializes and deserializes a SaveGame many times to get a sense of the speed and size that both formats produce. Unlike in previous JSON library comparison articles, an additional step is being performed on the JSON side. Since JsonUtility just produces a JSON string, we need to convert that string into a byte array in order to save it to disk, send it over a network, or make any other practical use of it. To do so, we use System.Text.Encoding.UTF8.GetBytes and then GetString to get the JSON string back.
using System; using System.Collections.Generic; using System.Text; using UnityEngine; [Serializable] public struct SaveGame { public string Name; public int HighScore; } class TestScript : MonoBehaviour { void Start() { var saveGame = new SaveGame { Name = "Speed Run", HighScore = 10000 }; // Warm up reflection JsonUtility.ToJson(saveGame); var stopwatch = new System.Diagnostics.Stopwatch(); const int reps = 1000000; var textEncoding = Encoding.UTF8; var jsonBytes = default(byte[]); var customBytes = default(byte[]); var jsonSaveGame = default(SaveGame); var customSaveGame = default(SaveGame); stopwatch.Start(); for (var i = 0; i < reps; ++i) { jsonBytes = textEncoding.GetBytes(JsonUtility.ToJson(saveGame)); } var jsonSerializeTime = stopwatch.ElapsedMilliseconds; stopwatch.Reset(); stopwatch.Start(); for (var i = 0; i < reps; ++i) { customBytes = SaveGameSerializer.Serialize(ref saveGame); } var customSerializeTime = stopwatch.ElapsedMilliseconds; stopwatch.Reset(); stopwatch.Start(); for (var i = 0; i < reps; ++i) { jsonSaveGame = JsonUtility.FromJson<SaveGame>(textEncoding.GetString(jsonBytes)); } var jsonDeserializeTime = stopwatch.ElapsedMilliseconds; stopwatch.Reset(); stopwatch.Start(); for (var i = 0; i < reps; ++i) { SaveGameSerializer.Deserialize(customBytes, ref customSaveGame); } var customDeserializeTime = stopwatch.ElapsedMilliseconds; Debug.LogFormat( "Format,SerializeTime,Deserialize Time\n" + "JSON,{0},{1}\n" + "Custom,{2},{3}\n", jsonSerializeTime, jsonDeserializeTime, customSerializeTime, customDeserializeTime ); Debug.LogFormat( "Format,Size\n" + "JSON,{0}\n" + "Custom,{1}\n", jsonBytes.Length, customBytes.Length ); Debug.Log( PrintSaveGame("JSON", jsonSaveGame) + PrintSaveGame("Custom", customSaveGame) ); } string PrintSaveGame(string title, SaveGame saveGame) { var builder = new StringBuilder(title); builder.Append(":\n\tName="); builder.Append(saveGame.Name); builder.Append('\n'); builder.Append("\tHighScore="); builder.Append(saveGame.HighScore); builder.Append('\n'); return builder.ToString(); } }
If you want to try out the test yourself, simply paste the above code into a TestScript.cs file in your Unity project’s Assets directory and attach it to the main camera game object in a new, empty project. Then build in non-development mode for 64-bit processors and run it windowed at 640×480 with fastest graphics. I ran it that way on this machine:
- 2.3 Ghz Intel Core i7-3615QM
- Mac OS X 10.12.1
- Unity 5.5.0f3, Mac OS X Standalone, x86_64, non-development
- 640×480, Fastest, Windowed
And here are the results I got:
| Format | Size |
|---|---|
| JSON | 38 |
| Custom | 28 |
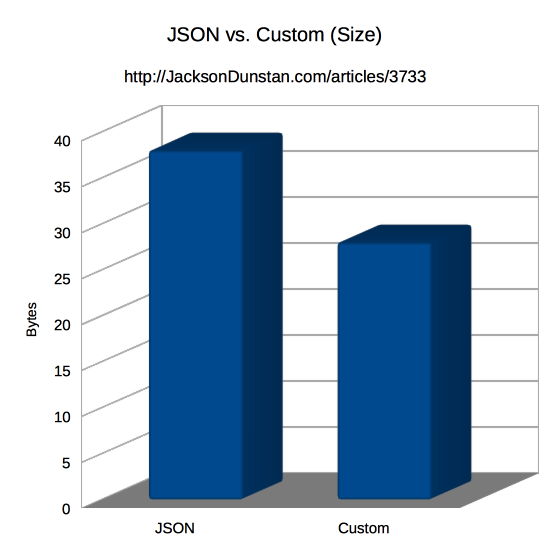
When it comes to size, the differences are pretty minor. JSON surely imposes some overhead, but the UTF-8 encoding better with the ASCII Name field in the example compared to the 2-byte-per-character encoding in the custom format. Again, it’d be simple to change the custom format to UTF-8 and the JSON would be larger if the name included non-ASCII characters. Likewise, the JSON would grow if the HighScore value was larger or had a negative sign.
| Format | SerializeTime | Deserialize Time |
|---|---|---|
| JSON | 2798 | 3487 |
| Custom | 85 | 88 |
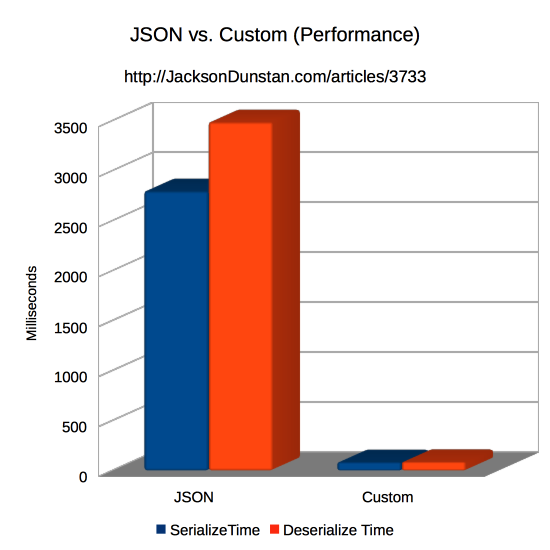
Speed, on the other hand, is a hands-down win for the custom format. It’s about 33x faster to serialize and 40x faster to deserialize! That’s a tremendous difference that dwarfs the mere 6x and 10x differences between the fastest and slowest JSON libraries I tested. The custom format is on a whole other level compared to JSON.
While JSON excels in areas like human readability, it’s clearly a lot slower and larger than this custom format. So if speed and size are your top priorities for a serialization format, don’t choose JSON.
#1 by Simon on January 30th, 2017 ·
Well if you want to show some crazy results you should start to compare json vs protobuf ;)
https://developers.google.com/protocol-buffers/docs/csharptutorial
#2 by jackson on January 30th, 2017 ·
That’s a good idea, and perhaps I will. Protobuf is definitely very well documented, powerful, and even reasonably popular. That said, I haven’t tried to use Protobuf in Unity for a couple of years, but this issue seems to suggest that you’d need to use an alternative implementation or old version. That’s not insurmountable, but definitely a hurdle.
#3 by benjamin guihaire on January 30th, 2017 ·
You might want to look at flatBuffers also
https://google.github.io/flatbuffers/
#4 by jackson on January 30th, 2017 ·
Great idea. This issue indicates that FlatBuffers don’t use anything that would break AOT in Unity, so it seems promising.
#5 by Josh Strike on January 30th, 2017 ·
Jackson, I always enjoy your articles on optimization, even though I’m stuck in AIR & JS and haven’t made the shift to Unity yet. This, though, is a perennial problem: Do you devise your own one-off serialization strategy, or go with something way too bulky, but that other programmers can read and that you can extend in the future?
JSON isn’t a byte stream. Yeah, it would be far more optimized if it defined and limited the number of characters to follow each key. Then again, file streams are more optimized when they don’t even have to define limits or types. The upshot to JSON is that we don’t have to rely on half a dozen serialization schemes to communicate between disparate languages and stacks, between front and back end, even to push data between separate databases. What JSON is good at is being the most efficient way of having mixed numeric and string keys referencing numbers and strings, nested, with no limitation to the data. It may be a kinda crummy way to read and write data for a fixed, specific purpose, but it’s the smallest way humans have devised to contain that kind of flexibility in mixed data structures; and it’s platform-agnostic. So while for any given purpose there may be a better way to write data, for all purposes it’s the standard. And thankfully there is a standard for this, because we live and walk on the rocks in a fractured enough landscape as it is.
#6 by jackson on January 30th, 2017 ·
Glad to hear you’re enjoying the articles, even while working outside of Unity and C#.
To your point about deciding between an off-the-shelf JSON library and writing a custom serializer, that’s up to you. The article’s only intention was to show that if you did write that custom serializer that you’d get a lot of speed and a little size out of it. As with all engineering, there are lots of tradeoffs to make. As you point out, when you deviate from a standard format to something custom that will harm interoperability with third parties. If that’s important to you then you should probably stick with JSON.
While this particular article showed a custom format, there are other general purpose serializers available. Google’s Protocol Buffers, BSON, Apache Thrift, MessagePack, and XML come to mind. All of them provide the JSON-like benefits of not needing to write your own serialization code and allowing for mixed and nested data types. If you’re interested in an alternative serialization format, there are plenty to choose from.
#7 by ms on February 22nd, 2017 ·
Hi Jackson,
Cool article.
For us newbies, wondering if you could possibly do an article delving into and discussing best practices and techniques with unsafe code and pointers in c#. Your article on unions in c# was very interesting and am curious to read more of what you have to say on the topic.
Thanks,
m
#8 by jackson on February 22nd, 2017 ·
Great idea! I’ve added it to my list of article ideas. :)
#9 by Macchia on July 17th, 2017 ·
What do you think about some Csv Reader for deserialization? Is it faster or slower than json? Also, i don’t know many libraries for csv reading, just an old one https://bravenewmethod.com/2014/09/13/lightweight-csv-reader-for-unity/
#10 by jackson on July 17th, 2017 ·
I haven’t tested the performance, but CSV can have some advantages over JSON. For one, there’s a lot less overhead due to syntax. JSON has a lot of curly braces, colons, commas, and quotes that just aren’t there in CSV. Unfortunately, the implementation you linked is really simple and nowhere near optimal. When parsing a text file like that it’s certainly easy to use a lot of built in string functions, but that’s also a good way to create a zillion tiny GC allocations. The string-based nature of CSV may even be its downfall. See this comment for some alternatives that will directly support non-string types like integers and floats, pack them into much smaller data sizes, and more efficiently serialize and deserialize them.
That said, I really like CSV for performance reporting. You’ve probably seen it in a lot of my performance tests on this site. It’s a super simple format that’s widely supported and allows me to easily copy/paste and make graphs and HTML tables from. I probably wouldn’t use it in production code though.