Better CPU Caching with Structs
While little utilized, C#’s struct type can come in really handy sometimes. Today’s article shows how to use it to get a lot more mileage out of modern CPUs’ caches to really boost your app’s performance. Read on for some quick tips!
The struct and class types seem really similar at first glance, but they’re represented very differently behind the scenes. One way this shows up is how arrays of each type are allocated in memory. With classes, an array is allocated with enough space to hold only pointers to the class instance objects. Those instances are allocated somewhere else. So an array of 10 classes will be about 80 bytes (8 bytes per pointer) all one contiguous block of memory, but the class instances will be located in memory somewhere else.
This means that as you loop over the array you are referencing the pointer in the array block of memory and then referencing the object somewhere else entirely. With each iteration you jump around arbitrarily in memory to find each object. While this is still much faster than, say, reading from a hard drive or SSD, it’s not nearly as fast as it can be. Enter struct.
With an array of struct, the array is allocated as a block big enough to hold all of the structs, not just pointers to them. As you loop over it, you read sequentially through this whole block of structs. A CPU loves this type of code because it loads large chunks of the array into its caches (e.g. L2) and your loop keeps reading straight out of the cache. This can be an order of magnitude faster than reading from RAM, but that’ll vary a lot by type of CPU.
To demonstrate, here’s a quick script that uses two types: PointStruct and PointClass. Each just holds two ints: X and Y. The script makes a large array of each and loops over them adding up their X and Y fields. In the end, the loop times are displayed on screen.
using System.Diagnostics; using UnityEngine; struct PointStruct { public int X; public int Y; } class PointClass { public int X; public int Y; } public class MainScript : MonoBehaviour { private string report; void Start() { const int size = 100000000; var structs = new PointStruct[size]; var classes = new PointClass[size]; for (var i = 0; i < size; ++i) { classes[i] = new PointClass(); } var sw = new Stopwatch(); var accum = 0; sw.Reset(); sw.Start(); for (var i = 0; i < size; ++i) { accum += structs[i].X; accum += structs[i].Y; } var structTime = sw.ElapsedMilliseconds; sw.Reset(); sw.Start(); for (var i = 0; i < size; ++i) { accum += classes[i].X; accum += classes[i].Y; } var classTime = sw.ElapsedMilliseconds; report = "Type,Time\n" + "Struct," + structTime + "\n" + "Class," + classTime; } void OnGUI() { GUI.TextArea(new Rect(0, 0, Screen.width, Screen.height), report); } }
If you want to try out the test yourself, simply paste the above code into a TestScript.cs file in your Unity project’s Assets directory and attach it to the main camera game object in a new, empty project. Then build in non-development mode for 64-bit processors and run it windowed at 640×480 with fastest graphics. I ran it that way on this machine:
- 2.8 Ghz Intel Core i7-4980HQ
- Windows 10
- Unity 5.2.4f1, Windows Standalone, x86_64, non-development
- 640×480, Fastest, Windowed
And here are the results I got:
| Type | Time |
|---|---|
| Struct | 113 |
| Class | 241 |
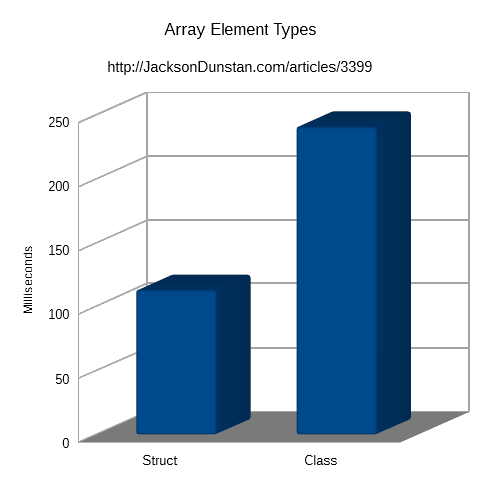
Clearly, the struct version was much quicker than the class version. Again, this will vary a lot based on CPU and where .NET/Mono decides to put the class instance objects in memory. In any case, the class version will never be as quick as the struct version because that it guaranteed to always take advantage of whatever CPU caching is available.
Keep this in mind next time you need to do a bulk operation on a lot of data. Using a struct just might speed things up a lot! If you’ve done this before, let me know in the comments how it’s worked out for you.
#1 by Marco on March 14th, 2016 ·
Great blog! Can we expect the same performance bump on arm (iOS) 64bit processors?
#2 by jackson on March 14th, 2016 ·
You should see a performance bump on ARM processors, both 32-bit and 64-bit. It may be smaller or larger than the x86 processor I tested with in the article though, so I recommend running the test script on your target devices to find out how much of a speedup you can expect.
#3 by ms on March 16th, 2017 ·
my testimony:
in one recent instance i was generating a world map using a class based represention, the profiler was showing a gc allocation of ~270.0kb in one frame — on changing several of the classes to structs that alloc was reduced to ~0.1kb … kinda’ neat!
#4 by João Hudson on November 13th, 2020 ·
I used this to develop a projectile system, where I put the mutable data in a struct array and the immutable data in a ScriptableObject. I had a good performance gain, but I wonder, wouldn’t using multiple arrays be even faster? For example:
from
Point[] points
to
int[] x and int[] y
#5 by jackson on November 13th, 2020 ·
That can be a lot faster if you’re using SIMD instructions to manipulate the data. Burst does these kinds of operations using structs like
float4and containers likeNativeArray. It could be a good fit for your mutable projectiles.