File I/O Performance Tips
At some point, every project ends up reading or writing to the file system. If you do anything more than storing a single blob of bytes (e.g. JSON text) then you’ll need to be very careful about performance. It’s easy to accidentally write code that takes way longer to read and write than it should and you won’t get any help from the compiler or from Unity. Today’s article reveals some of these traps so you won’t fall into them!
The .NET API provides us with lots of nice classes for writing to the file system. We have the abstract Stream and its FileStream child, the File class with static functions like Open, and convenient “readers” and “writers” like BinaryReader and BinaryWriter. The C# language itself provides the using block that allows for easy closing of the streams, readers, writers, and file handles. This sort of code is easily written, safely executed, and simple to maintain:
using (var stream = File.Open("/path/to/file", FileMode.OpenOrCreate)) { using (var writer = new BinaryWriter(stream, Encoding.UTF8)) { writer.Write("Hello, world!"); writer.Write(123); writer.Write(true); } }
In the end though, it all comes down to five basic operations:
- Open file:
File.Open - Read bytes:
stream.Read - Write bytes:
stream.Write - Seek to position:
stream.Positionorstream.Seek - Close file:
stream.Disposeorstream.Close
If you decompile the FileStream class you will see that stream.Position and stream.Seek do the same thing. Only the API differs. Also, stream.Dispose simply closes the file just like stream.Close.
With all of the simplicity that these streams, readers, and writers provide, it’s easy to overlook the performance implications. Each of these operations is just one function call, but the costs of them vary wildly. To put this to the test, I’ve written a little test app to try out each operation. Here’s what’s being tested today:
- Write 20 MB, one 4 KB “chunk” at a time
- Write 20 MB, one byte at a time
- Read 20 MB, one 4 KB “chunk” at a time
- Read 20 MB, one byte at a time
- Seek the stream’s
Positionas many times as chunks read/written - Open and close the file as many times as chunks read/written
Here’s the test script:
using System; using System.IO; using UnityEngine; class TestScript : MonoBehaviour { const string FileName = "TestFile"; const int FileSize = 1024 * 1024 * 20; const int ChunkSize = 1024 * 4; const int NumChunks = FileSize / ChunkSize; static readonly byte[] Chunk = new byte[ChunkSize]; string report = ""; void Start() { var path = Path.Combine(Application.persistentDataPath, FileName); if (File.Exists(path)) { File.Delete(path); } var stopwatch = new System.Diagnostics.Stopwatch(); long readChunkTime; long readByteTime; long writeChunkTime; long writeByteTime; long seekTime; long openCloseTime; using (var stream = File.Open(path, FileMode.OpenOrCreate)) { stopwatch.Start(); for (var i = 0; i < NumChunks; ++i) { stream.Write(Chunk, 0, ChunkSize); } writeChunkTime = stopwatch.ElapsedMilliseconds; } using (var stream = File.Open(path, FileMode.OpenOrCreate)) { stopwatch.Start(); for (var i = 0; i < FileSize; ++i) { stream.WriteByte(0); } writeByteTime = stopwatch.ElapsedMilliseconds; } using (var stream = File.Open(path, FileMode.OpenOrCreate)) { stopwatch.Reset(); stopwatch.Start(); for (var i = 0; i < NumChunks; ++i) { var numBytesRemain = ChunkSize; var offset = 0; while (numBytesRemain > 0) { var read = stream.Read(Chunk, offset, numBytesRemain); numBytesRemain -= read; offset += read; } } readChunkTime = stopwatch.ElapsedMilliseconds; } using (var stream = File.Open(path, FileMode.OpenOrCreate)) { stopwatch.Reset(); stopwatch.Start(); for (var i = 0; i < FileSize; ++i) { stream.ReadByte(); } readByteTime = stopwatch.ElapsedMilliseconds; } using (var stream = File.Open(path, FileMode.OpenOrCreate)) { stopwatch.Reset(); stopwatch.Start(); for (var i = 0; i < NumChunks; ++i) { stream.Position = stream.Position; } seekTime = stopwatch.ElapsedMilliseconds; } stopwatch.Reset(); stopwatch.Start(); for (var i = 0; i < NumChunks; ++i) { using (var stream = File.Open(path, FileMode.OpenOrCreate)) { } } openCloseTime = stopwatch.ElapsedMilliseconds; File.Delete(path); report = "Operation,Time\n" + "Write Chunk," + writeChunkTime + "\n" + "Write Byte," + writeByteTime + "\n" + "Read Chunk," + readChunkTime + "\n" + "Read Byte," + readByteTime + "\n" + "Seek," + seekTime + "\n" + "Open+Close," + openCloseTime + "\n"; } void OnGUI() { GUI.TextArea(new Rect(0, 0, Screen.width, Screen.height), report); } }
If you want to try out the test yourself, simply paste the above code into a TestScript.cs file in your Unity project’s Assets directory and attach it to the main camera game object in a new, empty project. Then build in non-development mode for 64-bit processors and run it windowed at 640×480 with fastest graphics. I ran it that way on this machine:
- 2.3 Ghz Intel Core i7-3615QM
- Mac OS X 10.11.2
- Apple SSD SM256E, HFS+ format
- Unity 5.3.0f4, Mac OS X Standalone, x86_64, non-development
- 640×480, Fastest, Windowed
And here are the results I got:
| Operation | Time |
|---|---|
| Write Chunk | 37 |
| Write Byte | 1415 |
| Read Chunk | 6 |
| Read Byte | 1228 |
| Seek | 2 |
| Open+Close | 243 |
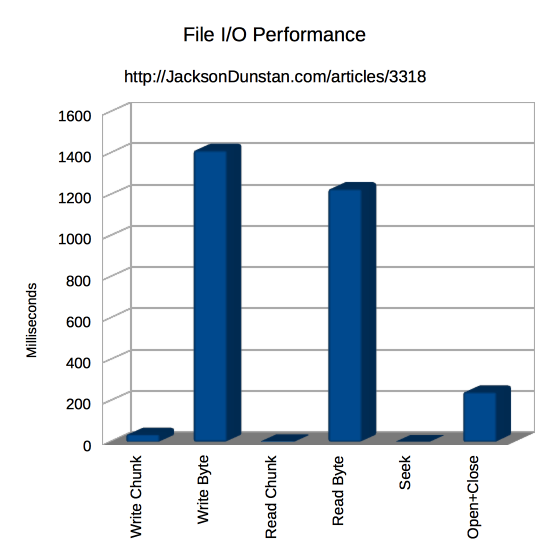
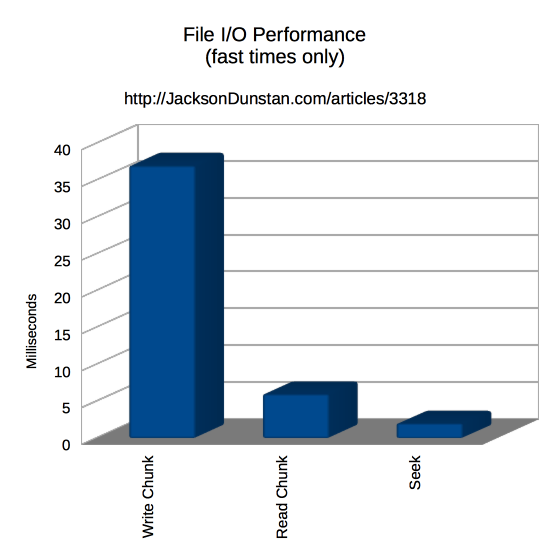
The results vary so much that it was necessary to break out the “fast” times into a separate chart just to be able to see them!
Reading and writing are tremendously more efficient if done in chunks rather than one byte at a time. While you probably won’t write just one byte, you might write a 4-byte integer or another value that would have almost as small of a chunk size. If you can, avoid this in favor of reading and writing large chunks and you’ll reap a 38x boost in writing and 205x boost in reading!
Seeking (either by setting Position or calling Seek) doesn’t read or write any bytes. It does, however, have a cost. While it’s not as much as any other operation, it does take a third as long as reading by 4 KB chunks. So it’s best to avoid seeking if possible to take advantage of buffering at various levels by reading and writing linearly through the file.
Lastly, opening and closing the file also don’t read or write any bytes but they too take time to do. Quite a lot of time, as it turns out! Opening and closing took 6.5x longer than writing the whole file by chunks and 40x longer than reading the whole file by chunks! That’s a really long time, especially considering that reading and writing are the important part and opening and closing are only requirements of the OS. So make sure that you’re not opening or closing files any more than you have to. You may even want to prefer larger files over many smaller files.
That wraps up today’s tips for file I/O performance. If you have any of your own to share, please leave a comment!
#1 by albina elvira on September 5th, 2016 ·
The path you entered, is too long. Enter a shorter path
File Name could not be found. Check the spelling of the filename,
and verify that the file location is correct.
#2 by hasmukh on November 21st, 2017 ·
I want to perform write operation using 100 thread and each thread writing 2Mb Data/second speed to file and every 5Mb Data collected than it will flush it into the file. When File Size becomes 256MB than we create new File, than which mechanism i need to use ? Will this operation is enough to manage by .NET file Stream or i Need to use win32 File IO ( Create File ) Mechanism to increase Writing speed without taking too much cpu usage?
#3 by jackson on November 21st, 2017 ·
FileStreamdoesn’t support writing from multiple threads, so you should probably look into native APIs likeCreateFileon Windows to support this scenario. Alternatively, you could buffer all your writes in RAM and then write them toFileStreamfrom a single thread. That’ll imply significant CPU and RAM overhead plus additional code complexity, but you’ll be able to avoid using OS-specific functionality.#4 by Ayyappa on September 21st, 2018 ·
Just as a note, here the file stream by default has a buffer size of 4k and the chunk size here matches with it. In case if the file stream is allocated with more buffer size, I guess it will give a much better performance.
Am I right Jack?
#5 by jackson on September 21st, 2018 ·
There are two times involved here, but only one is reported in the article. First there’s the time to write to the
FileStreamRAM buffer. Second there’s the time to write to the disk. Increasing the buffer size will definitely make the former faster, but the second will depend on your OS, file system, drivers, disk hardware, etc.#6 by Krzysztof on November 21st, 2018 ·
There is a bug in the seek fragment of code. In the loop, there is not increased position but constant assignment: stream.Position = stream.Position;.
#7 by jackson on November 21st, 2018 ·
Setting to the same value in the seeking loop is intentional. Looking through the call stack, it still leads to all the desired effects: flushing buffers, calls into native code, calls into OS code, etc. Here’s one such stack for Windows:
https://github.com/mono/mono/blob/master/mcs/class/corlib/System.IO/FileStream.cs#L376
https://github.com/mono/mono/blob/master/mcs/class/corlib/System.IO/FileStream.cs#L729
https://github.com/mono/mono/blob/master/mcs/class/corlib/System.IO/MonoIO.cs#L483
https://github.com/mono/mono/blob/master/mcs/class/corlib/System.IO/MonoIO.cs#L479
https://github.com/mono/mono/blob/3c74df566776f468366d96dd164dd1a6b3d780cc/mono/metadata/w32file.c#L567
https://github.com/mono/mono/blob/668933de7f65767d17dcf684f78d2f17824575f9/mono/metadata/w32file-win32.c#L130
The only result here is a call to
SetFilePointer, which results in no I/O regardless of the new position value:https://docs.microsoft.com/en-us/windows/desktop/api/fileapi/nf-fileapi-setfilepointer
https://stackoverflow.com/a/47989749
So in the case of this performance test, assigning the same value is useful to avoid adding overhead such as computing alternate values to the test code. That said, the test code probably should have cached the position value rather than calling its
getproperty in every loop as that call also entails a call into native and OS code. So the cost of seeking is overstated in the article, but it’s hard to say by how much.#8 by coffecat on November 30th, 2019 ·
Hello,
excuse me for posting a comment in this old article, I have a question.
You wanted to test the following:
-Write 20 MB, one 4 KB “chunk†at a time
but you initialized the byte[] as follows:
and then write only these 4KB instead of 20MB in 4KB chunks as shown:
therefore shouldn’t it be FileSize instead of ChunkSize?:
Maybe I’m wrong.
#9 by jackson on December 1st, 2019 ·
No worries about posting on an old article. :)
The goal is to write one 4 KB chunk at a time so
Chunkshould be 4 KB and thestream.Writecall should be passed a length of 4 KB. Both useChunkSize, which is the right size:1024 * 4.The next goal is to write 20 MB.
FileSizeis the right value for this:1024 * 1024 * 20. How many 4 KB chunks must we write such that we’ve written a total of 20 MB? The answer is 20 MB divided by 4 KB, which isNumChunkscomputed byFileSize / ChunkSize. Theforloop executes that many times, so we’ve achieved our goal.Hope this clears it up!
#10 by coffecat on December 2nd, 2019 ·
Oh, I realized after your first sentence that the loop iterates over NumChunks to achieve the 20MB, I didn’t notice that before.
I understand now, thank you for your reply.
I have a different question, what is the difference between FileStream’s method :
public override void Write (byte[] array, int offset, int count);and BinaryWriter’s method:
public virtual void Write (byte[] buffer, int index, int count);From what I can tell they both allow writing in chunks and they look very similar.
Is there any reason to use one over the other as you used FileStream here?
I apologize if these questions are too basic.
#11 by jackson on December 2nd, 2019 ·
A
BinaryWriteruses an “underlying stream” to write. That’s the stream you pass to its constructor. So there’s no way that it can improve performance since all it does is use the same public API that you could use directly withFileStream, assuming that’s the underlying stream you’re using. In fact, in Microsoft’s reference source you can see that it just calls the underlying stream’sWritefunction as a thin wrapper.The real reason to use
BinaryWriteris because it offers a lot more functionality thanFileStream. All those overloadedWritemethods taking various types are very convenient when writing out binary data.#12 by Chizl on November 16th, 2020 ·
I think you forgot it’s in a loop of “NumChunks” times.. So it’s appending the the same Chunk over and over FileSize / ChunkSize times.
#13 by jackson on November 16th, 2020 ·
This was intentional so that each test would write a total of 20 MB, as stated before the test script. For the “Write Byte” test, this is simply
20 * 1024 * 1024single byte writes. If I wrote that many 4 KB chunk writes, I’d have written4 * 1024times as much data. If I removed the loop, I’d have written only 4 KB of data. In order to write the same amount of data in both tests, I need to writeFileSize / ChunkSize4 KB chunks.