C++ For C# Developers: Part 49 – Ranges and Parallel Algorithms
Generic algorithms have been available in C++ for decades, but the last two versions of the language have really ramped up the functionality. C++17 added support for parallel execution of generic algorithms to easily take advantage of multi-core CPUs. Then C++20 added support for ranges, a composable version of generic algorithms that’s even closer to LINQ in C#. Today we’ll explore both of these!
Table of Contents
- Part 1: Introduction
- Part 2: Primitive Types and Literals
- Part 3: Variables and Initialization
- Part 4: Functions
- Part 5: Build Model
- Part 6: Control Flow
- Part 7: Pointers, Arrays, and Strings
- Part 8: References
- Part 9: Enumerations
- Part 10: Struct Basics
- Part 11: Struct Functions
- Part 12: Constructors and Destructors
- Part 13: Initialization
- Part 14: Inheritance
- Part 15: Struct and Class Permissions
- Part 16: Struct and Class Wrap-up
- Part 17: Namespaces
- Part 18: Exceptions
- Part 19: Dynamic Allocation
- Part 20: Implicit Type Conversion
- Part 21: Casting and RTTI
- Part 22: Lambdas
- Part 23: Compile-Time Programming
- Part 24: Preprocessor
- Part 25: Intro to Templates
- Part 26: Template Parameters
- Part 27: Template Deduction and Specialization
- Part 28: Variadic Templates
- Part 29: Template Constraints
- Part 30: Type Aliases
- Part 31: Destructuring and Attributes
- Part 32: Thread-Local Storage and Volatile
- Part 33: Alignment, Assembly, and Language Linkage
- Part 34: Fold Expressions and Elaborated Type Specifiers
- Part 35: Modules, The New Build Model
- Part 36: Coroutines
- Part 37: Missing Language Features
- Part 38: C Standard Library
- Part 39: Language Support Library
- Part 40: Utilities Library
- Part 41: System Integration Library
- Part 42: Numbers Library
- Part 43: Threading Library
- Part 44: Strings Library
- Part 45: Array Containers Library
- Part 46: Other Containers Library
- Part 47: Containers Library Wrapup
- Part 48: Algorithms Library
- Part 49: Ranges and Parallel Algorithms
- Part 50: I/O Library
- Part 51: Missing Library Features
- Part 52: Idioms and Best Practices
- Part 53: Conclusion
Parallel Algorithms
Similar to ParallelEnumerable in .NET 5.0’s version of LINQ, C++17 added overloads to many generic algorithms to enable specifying their “execution policy.” C++ allows specifying two related factors: parallelism and sequencing. “Parallel” refers to whether the operations that make up the algorithm may be performed in parallel on multiple threads. “Unsequenced” refers to whether the operations may be vectorized such as with the CPU’s SIMD instructions to operate on multiple elements of the collection at once. This table shows the options:
| Execution Policy | Global Instance | Parallel | Vectorized | C++ Version |
|---|---|---|---|---|
std::execution::sequenced_policy |
std::execution::seq |
No | No | C++17 |
std::execution::unsequenced_policy |
std::execution::unseq |
No | Yes | C++20 |
std::execution::parallel_policy |
std::execution::par |
Yes | No | C++17 |
std::execution::parallel_unsequenced_policy |
std::execution::par_unseq |
Yes | Yes | C++17 |
The fewer restrictions we put on the algorithm, the faster it may perform. The defaults we’ve had for decades are equivalent to seq but we can enable parallelism and vectorization with par_unseq or just one with unseq or par.
The following program benchmarks std::sort on a std::vector<uint32_t> containing one million random integers. It uses std::sort in its default form as well as with all of the execution policies. It makes use of several C++ Standard Library features including random number generation and time-checking:
#include <execution> #include <algorithm> #include <chrono> #include <vector> #include <cassert> #include <random> #include <limits> template <typename TExecutionPolicy> void Sort(std::vector<uint32_t>& v, const char* label, const TExecutionPolicy& ep) { // Randomize the array std::random_device rd; std::mt19937 gen{ rd() }; std::uniform_int_distribution dist{ std::numeric_limits<uint32_t>::min(), std::numeric_limits<uint32_t>::max() }; for (uint32_t i = 0; i < static_cast<uint32_t>(v.size()); ++i) { v[i] = dist(gen); } // Take the time before sorting std::chrono::steady_clock clock{}; auto before{ clock.now() }; // Use normal sort if execution policy is null // Otherwise use sort that has an execution policy if constexpr (std::is_same_v<TExecutionPolicy, std::nullptr_t>) { std::sort(v.begin(), v.end()); } else { std::sort(ep, v.begin(), v.end()); } // Take the time after sorting auto after{ clock.now() }; auto elapsed{ after - before }; auto ms{ std::chrono::duration_cast<std::chrono::milliseconds>(elapsed) }; DebugLog(label, ms); // Make sure the array is actually sorted assert(std::is_sorted(v.begin(), v.end())); } int main() { std::vector<uint32_t> v{}; v.resize(1000000); Sort(v, "default", nullptr); Sort(v, "sequenced", std::execution::seq); Sort(v, "parallel", std::execution::par); Sort(v, "unseq", std::execution::unseq); Sort(v, "parallel_unsequenced", std::execution::par_unseq); }
Compiling this with Microsoft Visual Studio 16.9.4 in Release mode and running on Windows 10 20H2 with an Intel Core i5-1135G7 yielded these results:
| Execution Policy | Time |
|---|---|
| default | 74ms |
sequenced |
74ms |
parallel |
23ms |
unseq |
73ms |
parallel_unsequenced |
16ms |
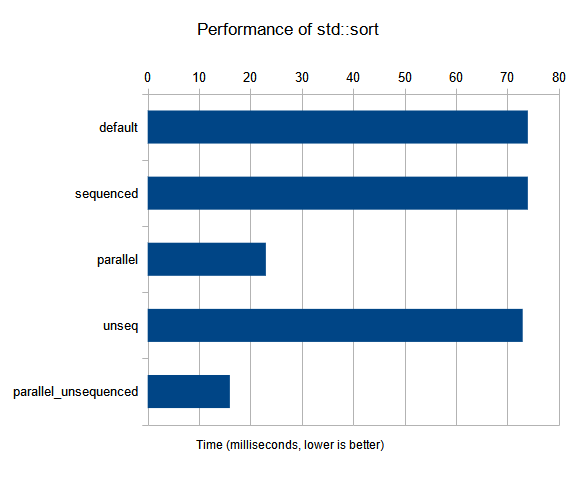
We see here that sequenced really is the same as not specifying an execution policy at all. Opting for unseq hardly made an improvement, but parallel cut the time by nearly 70%! parallel_unsequenced went even further and cut the time by over 78%!
A lot of these results will depend on compiler, Standard Library implementation, data type, container contents, OS, CPU and other hardware, and the chosen algorithm. As always, it’s best to measure the actual scenario being optimized to gain the most relevant timing data.
That said, it’s clear from this timing that at least the std::sort algorithm on integers lends itself to parallelism. Rather than painstakingly implementing our own parallel sort function, we can simply pass an execution policy to std::sort and take advantage of the library version with any data type and any container type. Here’s a few examples:
#include <execution> #include <algorithm> #include <vector> #include <deque> std::vector<uint32_t> v{}; v.resize(1000000); std::iota(v.begin(), v.end(), 10); // Parallel check that a function returns true for all elements DebugLog( std::all_of( std::execution::par_unseq, v.begin(), v.end(), [](uint32_t x) { return x >= 10; })); // true // Parallel search for an element that a function returns true for DebugLog( std::distance( v.begin(), std::find_if( std::execution::par_unseq, v.begin(), v.end(), [](uint32_t x) { return x == 100; }))); // 90 // Parallel transform of elements into another container // Output container even has a different type: a double-ended queue std::deque<uint32_t> d{}; d.resize(v.size()); std::transform( std::execution::par_unseq, v.begin(), v.end(), d.begin(), [](uint32_t x) { return x * 2; }); DebugLog(d[0], d[1], d[2], d[3], d[4]); // 20, 22, 24, 26, 28
That’s really all there is to parallel and unsequenced algorithms. The goal is to make parallelism easy, so there’s no need to manage threads or data synchronization at all. Just pass an appropriate execution policy and let the Standard Library take care of the implementation.
Ranges
The “ranges” portion of the C++20 Standard Library adds an alternative approach to the same generic algorithms we’ve already seen. For example, std::ranges::sort acts like std::sort except that it takes a “range” rather than a pair of iterators:
#include <ranges> #include <algorithm> #include <vector> std::vector<int> v{ 4, 5, 2, 1, 3 }; // Only pass a range, not a pair of iterators std::ranges::sort(v); DebugLog(v[0], v[1], v[2], v[3], v[4]); // 1, 2, 3, 4, 5
While not as flexible as the pairs of iterators we’ve passed to algorithms so far, this approach is less error-prone as we might avoid accidentally passing mismatching iterators and causing undefined behavior as an algorithm reads beyond the beginning or end of a container:
#include <algorithm> #include <vector> std::vector<int> v{ 4, 5, 2, 1, 3 }; std::vector<int> v2{ 4, 5, 2, 1, 3 }; // Pass an iterator to the beginning of v but the end of v2 // find() can never get to the second iterator from the first by calling ++ // It'll read off the end of v, causing undefined behavior like a crash auto it{ std::find(v.begin(), v2.end(), 6) }; DebugLog("found?", it == v.end()); // ???
Another new feature is support for “projection” functions. We can specify a function for elements to be passed to and that return the value to use, similar to std::transform. Here we use a projection function to sort a player’s points rather than the Player object itself:
#include <ranges> #include <algorithm> #include <vector> struct Player { const char* Name; int NumPoints; }; std::vector<Player> p{ {"Alice", 30}, {"Bob", 20}, {"Carol", 100} }; std::ranges::sort( p, // Range to sort {}, // Default comparison [](const Player& x) { return x.NumPoints; }); // Projection function DebugLog(p[0].Name, p[1].Name, p[2].Name); // Bob, Alice, Carol
These are incremental improvements to the classic generic algorithms library, but where ranges really shine is with their system of “views.” A view is like an IEnumerable in C# LINQ. It’s not a collection, but instead a lazily-evaluated view of something that might be a collection. Combined with some operator overloading, we can easily compose many algorithms into one:
#include <ranges> #include <algorithm> #include <vector> using namespace std::ranges::views; struct Player { const char* Name; int NumPoints; }; std::vector<Player> players{ {"Alice", 30}, {"Bob", 20}, {"Carol", 100} }; // Filter for players with more than 25 points // Then transform players to remove a point // Then reverse the order of the players auto result = players | filter([](Player p) { return p.NumPoints > 25; }) | transform([](Player p) { p.NumPoints--; return p; }) | reverse; for (const Player& p : result) { DebugLog(p.Name, p.NumPoints); // "Carol, 99" then "Alice, 29" }
The result here isn’t evaluated until the range-based for loop actually iterates through the view. The view itself is composed via the overloaded | operator out of several “view adapters”: filter, transform, and reverse. These view adapters are really just terse ways to create views. In this case, the filter function creates and returns a filter_view, transform creates a transform_view, and reverse creates a reverse_view.
It’s worth noting that this lazy evaluation can be more efficient than the eager version we’ve seen so far. That’s because there’s no need to allocate full-size temporary buffers to hold intermediate results. Instead, we simply need the current value being evaluated. Consider the classic version of the above ranges code:
#include <ranges> #include <algorithm> #include <vector> using namespace std::ranges::views; struct Player { const char* Name; int NumPoints; }; std::vector<Player> players{ {"Alice", 30}, {"Bob", 20}, {"Carol", 100} }; // Filter for players with more than 25 points std::vector<Player> output{}; std::copy_if( players.begin(), players.end(), std::back_inserter(output), [](Player p) { return p.NumPoints > 25; }); // Then transform players to remove a point std::transform( output.begin(), output.end(), output.begin(), [](Player p) { p.NumPoints--; return p; }); // Then reverse the order of the players std::reverse(output.begin(), output.end()); for (const Player& p : output) { DebugLog(p.Name, p.NumPoints); // "Carol, 99" then "Alice, 29" }
In order to use std::filter and std::transform, we needed to provide a place to put the output. We didn’t want to overwrite the existing players so we needed to create output. This could have been really inefficient for a large amount of data. It also would have required a lot of dynamic growing of the output as elements were inserted by filter. We could approximate with reserve to limit the number of grow operations, but there’s often no fast, precise, and general way to know how much space to reserve.
Ranges eliminate this problem by operating on one element at a time. There’s never a need for a buffer that can hold all the elements. Instead, we’re just allocating enough for the current element.
We’ve seen that each kind of iterator has its own “tag” class that it derives from and then C++20 provides concept equivalents of each of these. The same is also true for ranges. The major difference is that input_or_output has been replaced with just range:
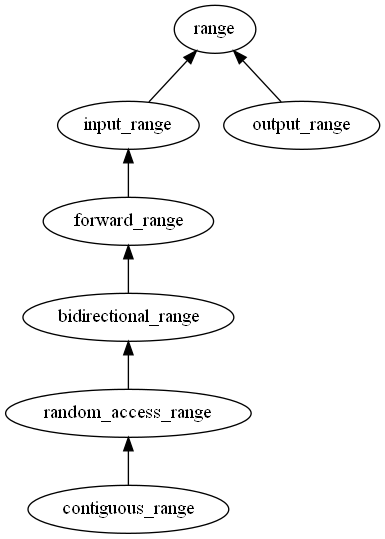
A wide variety of ranges, views, and view adapters are available. The ranges library provides what’s essentially a mirror version of all of the generic algorithms we’ve seen so far. Thankfully, all of the naming also mirrors the existing functions so it’s easy to find a range equivalent.
Conclusion
C++17 allows us to specify how we want our generic algorithms to run. We can run them in the classic single-threaded way with no vector operations or we can opt in to multi-threading and vector operations. Doing so is dead simple and can greatly improve the performance of the algorithms.
C++20 adds ranges, a lazy-evaluated version of generic algorithms. It’s much more composable, less error-prone, and sometimes even more efficient than the classic algorithms. It ends up resembling a much faster version of LINQ that eschews all the garbage creation and virtual function calls.
In the end, it’s our choice which of these options we want to use. All of them support a wide variety of common algorithms. We’re even free to build our own and have them work with the algorithms provided by the C++ Standard Library. All these options combine to significantly reduce the number of “raw” loops we need to write in C++.