NativeIntPtr and NativeLongPtr: Part 2
Last week’s article introduced two new native collection types: NativeIntPtr and NativeLongPtr. These were useful for both IJob and IJobParallelFor jobs, but performance was degraded in IJobParallelFor. Today we’ll remedy that, explore some more aspects of Unity’s native collection and job systems, and learn more about CPU caches along the way.
Recap
Last week we created NativeIntPtr and NativeLongPtr as pointers to a single int or long in native/unmanaged memory. These were usable with IJob jobs, but not IJobParallelFor jobs because they couldn’t restrict usage to a contigous range or only atomic writes.
To alleviate this issue, we created NativeIntPtr.Parallel and NativeLongPtr.Parallel. These could be created by NativeIntPtr and NativeLongPtr to point to the same native int or long in native/unmanaged memory. The difference is that these types restrict to only atomic write operations by adding [NativeContainerIsAtomicWriteOnly] and only calling methods of the Interlocked class.
Unfortunately, atomic operations are necessarily more expensive than non-atomic operations. This meant that while a NativeIntPtr.Parallel could be used in an IJobParallelFor job, using it would be slower than using a NativeIntPtr in an IJob.
A new design
The core issue that with the NativeIntPtr.Parallel design is that there is still contention between all the threads running the IJobParallelFor job for access to the memory holding the int. This forced us to use atomic operations to resolve the contention issue. Today we’ll take another approach to solving this issue.
In today’s design we’ll make a classic CPU-memory tradeoff. To improve CPU performance, we’ll use more memory. Instead of storing just one int, we’ll store one int for every thread that Unity’s job system could run. That value is exposed to us by the const JobsUtility.MaxJobThreadCount value and currently stands at 128 as of Unity 2018.2. At four bytes per int, this means we’ll be using 128 × 4 = 512 bytes of memory instead of just 4.
Because this is a tradeoff and not strictly an improvement, we’ll create a new NativePerJobThreadIntPtr type rather than modifying NativeIntPtr. Here’s how the memory layout for a single NativePerJobThreadIntPtr with a Value of 18 will look with this approach:
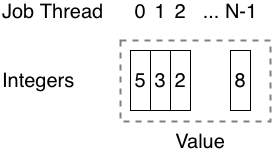
Here we see an unmanaged/native array of JobsUtility.MaxJobThreadCount contiguous int values. Each job thread corresponds to one element of the array. This means that even if all the job threads of an IJobParallelFor were modifying the NativePerJobThreadIntPtr.Parallel at the same time that there would be no contention. This is because they would each be accessing different elements of the array of int values.
So far we have a bunch of int values, but NativePerJobThreadIntPtr and NativePerJobThreadIntPtr.Parallel are supposed to represent one int value. This seems like a mismatch, but it’s not because of the way we’ll treat the array. When the get for NativePerJobThreadIntPtr.Value is called, we’ll sum up all the int values of the array and return that. In the above diagram, we have 5 + 2 + 3 + (zeroes) + 8 = 18.
There are a couple properties of the code that help us maintain this single-value illusion for the user of these types:
First, remember that NativePerJobThreadIntPtr.Parallel only has atomic write operations. There’s no way to directly read the value as that would break Unity’s restrictions on types used in an IJobParallelFor. All reading of the value must occur outside of the IJobParallelFor in either an IJob or the main thread by accessing the NativePerJobThreadIntPtr.
Second, remember that NativePerJobThreadIntPtr.Parallel only allows for relative changes to a value, not absolute setting of the value. There are Increment, Decrement, and Add methods, but not Set. This means that changes to one int value are only an offset to the overall sum. If we allowed a Set then we’d have contention for all the other int values since they’d need to all be set to 0 to accommodate the whole-value change.
Problems with this design
It’s true that the above design doesn’t have any contention for individual elements of the int array, but only for a computer with no CPU data cache. Since that hasn’t been the case since the 1980s, we need to be concerned with how the CPU will behave when we have a bunch of job threads modifying the elements of the array.
The issue here is called false sharing and occurs because of the way CPU data caches work. Cache is filled with so-called “lines” of data, typically 64 bytes long. When we read one byte of memory at address 100, the CPU will actually load 64 bytes of memory from RAM at addresses 100-163.
Now say another CPU core with its own data cache also reads a byte at address 100. This will mean that both CPU cores have 100-163 in their own caches. If one of these cores writes to this cached memory at address 100 then the CPU must copy this cache line to the other CPU core so that it has a consistent view of the system’s memory.
This copy is expensive and we want to avoid it. Unfortunately, it’ll happen constantly with our new design. If we have job threads 0 and 1 modifying the NativePerJobThreadIntPtr.Parallel at the same time then they’ll both be reading, modifying, and writing memory of the same cache line and continually cause the CPU to copy cache lines between the cores those threads are running on.
A better design
The solution to the “false sharing” problem is the same tradeoff: memory for CPU. If we can guarantee that modifying an int doesn’t mean changing memory that’s in another thread’s cache line then the CPU won’t ever need to copy any cache lines between cores.
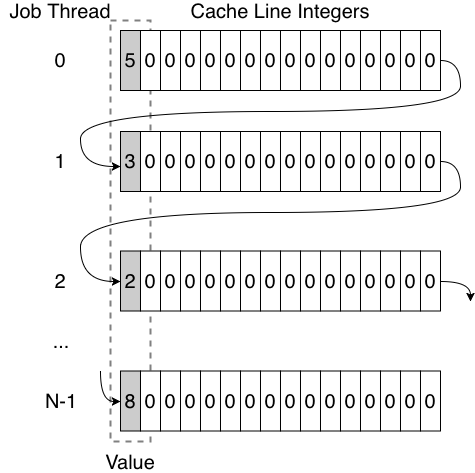
All we need to do to make this happen is to increase our per-thread allocation from one int to one cache line. Unity helpfully provides us another const value for this: JobsUtility.CacheLineSize. Since this is set to 64, our memory usage increases to 128 (max job threads) × 64 = 8192 bytes (8 KB). That’s a 2048x increase over the original NativeIntPtr design, but still a small amount for a modern computer with at least hundreds of megabytes of RAM so the tradeoff is often worthwhile.
Here’s how the new memory layout looks for the same 18 value. Note that there is only one array, so each row continues the previous row’s values.
Implementation
Now let’s look at how to put this design into practice. First, we allocate more than just one int worth of memory in the constructor. Now we allocate one cache line per job thread:
m_Buffer = (int*)UnsafeUtility.Malloc( JobsUtility.CacheLineSize * JobsUtility.MaxJobThreadCount, UnsafeUtility.AlignOf<int>(), allocator);
Next let’s compute a useful value: the number of int values per cache line.
private const int IntsPerCacheLine = JobsUtility.CacheLineSize / sizeof(int);
Now can use this to make the get for Value return the sum of each thread’s values:
public int Value { get { RequireReadAccess(); int value = 0; for (int i = 0; i < JobsUtility.MaxJobThreadCount; ++i) { value += m_Buffer[IntsPerCacheLine * i]; } return value; } }
And we’ll make the set for Value set the first thread’s value and clear all the others:
public int Value { [WriteAccessRequired] set { RequireWriteAccess(); *m_Buffer = value; for (int i = 1; i < JobsUtility.MaxJobThreadCount; ++i) { m_Buffer[IntsPerCacheLine * i] = 0; } } }
Now we turn to NativePerJobThreadIntPtr.Parallel to make the necessary changes there. First, we add a field for Unity to automatically fill in the job thread index:
[NativeSetThreadIndex] internal int m_ThreadIndex;
We need to initialize this to something in the constructor, so we’ll choose 0 since it’s always valid and the value will only be used outside of IJobParallelFor where there’s no contention anyhow.
m_ThreadIndex = 0;
Finally, we rewrite Increment, Decrement, and Add to read, modify, and write the int for the job thread index. These are the non-atomic operations that don’t use Interlocked and the payoff for all our efforts and memory usage:
[WriteAccessRequired] public void Increment() { RequireWriteAccess(); m_Buffer[IntsPerCacheLine * m_ThreadIndex]++; } [WriteAccessRequired] public void Decrement() { RequireWriteAccess(); m_Buffer[IntsPerCacheLine * m_ThreadIndex]--; } [WriteAccessRequired] public void Add(int value) { RequireWriteAccess(); m_Buffer[IntsPerCacheLine * m_ThreadIndex] += value; }
That’s all there is to it. Usage of NativePerJobThreadIntPtr is identical to NativeIntPtr since only internal details were changed. NativePerJobThreadLongPtr is omitted here for brevity, but it’s essentially the same except for using long instead of int.
Conclusion
Today we’ve seen one example of a CPU-memory tradeoff. In this case we gained CPU performance by removing atomic operations in favor of regular, non-atomic operations. The downside is that we’re using more than 2000x as much memory now. In an attempt to have the best of both worlds, we’ve simply created two pairs of types: NativeIntPtr + NativeLongPtr and NativePerJobThreadIntPtr + NativePerJobThreadLongPtr. Both are now available on the NativeCollections GitHub repository, so you can choose which is right for each use case in your projects.
Note: This article and its predecessor as well as the resulting NativeIntPtr and NativePerJobThreadIntPtr types expand upon the NativeCounter and NativePerThreadCounter types from the Unity ECS samples as described here.
#1 by JamesM on October 22nd, 2018 ·
In order to avoid false sharing shouldn’t that the steps be JobUtitility.CacheLineSize e.g.
#2 by jackson on October 22nd, 2018 ·
Yes, but that’s done for us by the compiler. The type of
m_Bufferisint*, so each index skipssizeof(int)bytes.#3 by JamesM on October 22nd, 2018 ·
> The downside is that we’re using more than 2000x as much memory now
It’s still only 8kb, the
MaxJobThreadCountseems awfully high is this something you can tweak in the editor?#4 by jackson on October 22nd, 2018 ·
Right, as noted in the article it’s likely a worthy tradeoff:
JobsUtility.MaxJobThreadCountis a compile-timeconstset by Unity that, as far as I know, we don’t have any control over.#5 by JamesM on October 22nd, 2018 ·
Did you get any benchmark numbers from this?
#6 by jackson on October 22nd, 2018 ·
Not at the time I wrote the article, but I just put together a quick test to sum a
NativeArray<int>with 10,000 elements using anIJobParallelForand either aNativeIntPtr.Parallelor aNativePerJobThreadIntPtr.Parallel. Here are the results I got on a 2.7 GHz Intel Core-i7 (6820HQ):So the improvements in this version result in a 5-6x speedup in my test environment.