String Keys vs. Int Keys
Now that we know you can use int keys with Object, it’s time to test whether or not this is any faster than String keys. Today’s article does just that and also tests int and String keys with Dictionary.
First of all, Dictionary has a lot of the same strange behavior regarding keys that Object has. For example, dict[3] = 1 then dict["3"] = 2 results in 2 overriding 1 but the key remaining the int 3. But dict["03"] = 10 results in a String key "03" with the int value 10.
Now to test the performance of int keys against String keys. The following test app builds an Object and a Dictionary of various sizes—1 through 100,000 in 10x increments—and then reads each key-value pair via an Array of indices.
package { import flash.display.*; import flash.utils.*; import flash.text.*; public class KeyTypes extends Sprite { private var logger:TextField = new TextField(); private function row(...cols): void { logger.appendText(cols.join(",") + "\n"); } public function KeyTypes() { stage.align = StageAlign.TOP_LEFT; stage.scaleMode = StageScaleMode.NO_SCALE; logger = new TextField(); logger.autoSize = TextFieldAutoSize.LEFT; addChild(logger); init(); } private function init(): void { var REPS:int = 1000000; var i:int; var str:String; var beforeTime:int; var afterTime:int; var objTime:int; var dictTime:int; var obj:Object; var dict:Dictionary; var indices:Array; row("Size", "Key Type", "Object Time", "Dictionary Time"); for each (var size:int in [1, 10, 100, 1000, 10000, 100000]) { indices = new Array(REPS); for (i = 0; i < REPS; ++i) { indices[i] = i % size; } obj = new Object(); dict = new Dictionary(); for (i = 0; i < size; ++i) { obj[i] = i; dict[i] = i; } beforeTime = getTimer(); for (i = 0; i < REPS; ++i) { obj[indices[i]]; } afterTime = getTimer(); objTime = (afterTime - beforeTime) / (Number(REPS)/1000000); beforeTime = getTimer(); for (i = 0; i < REPS; ++i) { dict[indices[i]]; } afterTime = getTimer(); dictTime = (afterTime - beforeTime) / (Number(REPS)/1000000); row(size, "Int", objTime, dictTime); indices = new Array(REPS); for (i = 0; i < REPS; ++i) { indices[i] = "" + (i%size); } obj = new Object(); dict = new Dictionary(); for (i = 0; i < size; ++i) { str = "" + i; dict[i] = i; dict[str] = i; } beforeTime = getTimer(); for (i = 0; i < REPS; ++i) { obj[indices[i]]; } afterTime = getTimer(); objTime = (afterTime - beforeTime) / (Number(REPS)/1000000); beforeTime = getTimer(); for (i = 0; i < REPS; ++i) { dict[indices[i]]; } afterTime = getTimer(); dictTime = (afterTime - beforeTime) / (Number(REPS)/1000000); row(size, "String", objTime, dictTime); } } } }
I ran this test in the following environment:
- Release version of Flash Player 12.0.0.70
- 2.3 Ghz Intel Core i7-3615QM
- Mac OS X 10.9.1
- Google Chrome 33.0.1750.146
- ASC 2.0.0 build 354071 (
-debug=false -verbose-stacktraces=false -inline -optimize=true)
And here are the results I got:
| Size | Key Type | Object Time | Dictionary Time |
|---|---|---|---|
| 1 | Int | 31 | 30 |
| 1 | String | 90 | 82 |
| 10 | Int | 30 | 30 |
| 10 | String | 98 | 86 |
| 100 | Int | 30 | 30 |
| 100 | String | 218 | 206 |
| 1000 | Int | 31 | 30 |
| 1000 | String | 155 | 135 |
| 10000 | Int | 31 | 30 |
| 10000 | String | 168 | 150 |
| 100000 | Int | 30 | 30 |
| 100000 | String | 222 | 203 |
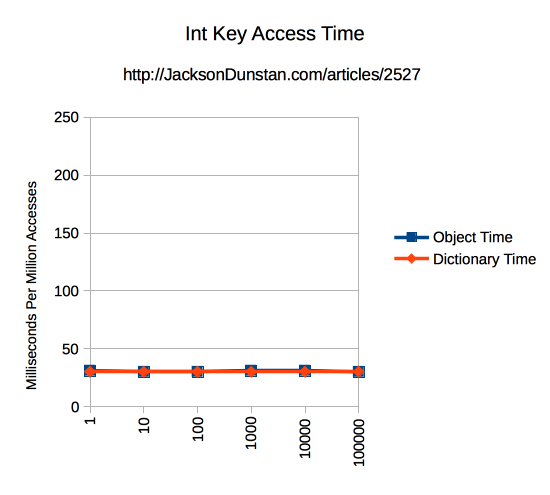
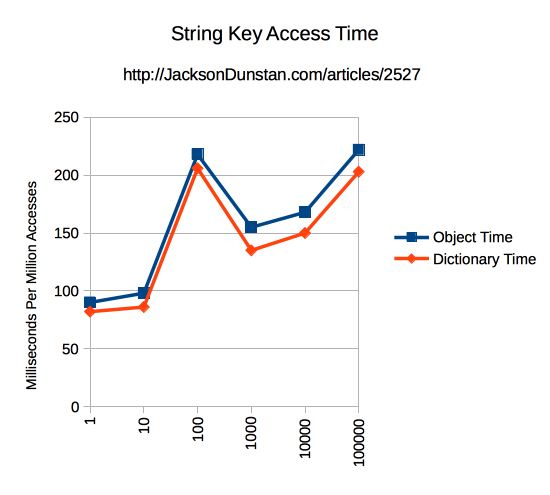
Performance of int keys clearly differs from String keys in two ways. In the test environment int keys take about 30 milliseconds regardless of the index being read or the size of the Object or Dictionary being read from. String, on the other hand, takes a minimum of about 82 milliseconds with a Dictionary of size 1, rises slightly until 10, jumps to 200 at 100, falls to 150 at 1000, then rises back to 200 by 100,000. So the performance is both slow and inconsistent across sizes. Object and Dictionary, however, mirror each other closely over the whole range of sizes. Dictionary is slightly faster at all times.
Clearly, Object and Dictionary are implemented with two very different strategies for keys. One is for Array-like access via int keys. The other is for map-like access via String keys. Given that the performance of int keys is so much better than String keys, automatically converting from String keys to int keys, as seen in the previous article, makes more sense. It’s an optimization that hopefully won’t cause any strange behavior in your program, but certainly could if you don’t understand the flowchart.
For now, the advice is the same as it’s always been: use int keys when you need a map that’s based on indices and String keys when you need a map that’s based on names. However, if your map’s data is sequential in nature you should probably be using a Vector or an Array.
Spot a bug? Have a question or suggestion? Post a comment!
#1 by Ben on March 10th, 2014
I can confirm the results on Win 7 (i7-3770 @ 3.4 GHZ, 32 GB RAM, compiled with AIR SDK 3.9)
1,Int,20,22
1,String,65,73
10,Int,20,22
10,String,66,60
100,Int,21,22
100,String,131,127
1000,Int,19,22
1000,String,156,151
10000,Int,19,23
10000,String,152,147
100000,Int,20,23
100000,String,182,174
#2 by henke37 on March 10th, 2014
Next up: Object and Dictionary vs. Vector and Array.
#3 by jackson on March 10th, 2014
Yep, that’s probably next. :)
#4 by Antoine on April 16th, 2014
Good one.
I am by no mean a data structure expert but this is my humble explanation of the above results : the difference in the cost of access time can probably be explained by the underlying algorithm used to map keys and values.
Ultimately Object/Dictionary have to be using an hash table that uses a hashing function to get integers from keys and use them as array indices. Hashing functions usually generate collisions therefore the need arises for a linear search for the right value (probably explaining the larger access time). When a certain “load” is reached, the hashtable grows size and the hashing function would typically generate less collisions (explained why accessing becomes faster after size becomes greater than 100)
When using integer as keys, the hashing function most likely has an optimization (just use the integer as the index for the table) that helps using collisions. Because of that I would be curious to see the performance of integer keys for values that aren’t contiguous. Also measuring the performance of insertion might be interesting (given that hash table need to rehash when growing).
BTW The Virtual Machine source code has been open-sourced by Adobe and I believe this file contains the Dictionary insert/find implementation :
https://github.com/adobe-flash/avmplus/blob/master/core/avmplusHashtable.cpp
I don’t understand it all but it’s a an interesting read!
#5 by jackson on April 16th, 2014
I wrote an article quite a while ago that discussed the two parts of an
Array: the densely-packed portion at the beginning (i.e. 0, 1, 2, …) and the sparsely-packed hash table after that (e.g. 21, 88, 103, …). Performance is much better in the densely-packed portion due to the lack of any hash overhead, as you point out.#6 by Kyle on June 20th, 2017
Very helpful. Thanks!
#7 by Gimmick on December 31st, 2017
What’s the performance hit for constructing the strings themselves? By allocating strings in
str = "" + i, wouldn’t that contribute to the time required?#8 by jackson on January 2nd, 2018
Yes, the time required to build the string itself will unfairly add to the total string time. It’s been almost four years since I wrote this, but I vaguely remember considering alternatives such as pre-building the strings and storing them in an array. That turned out to be even more expensive than building the strings on the fly. Another alternative is to use four loops: (A) the existing string loop, (B) the existing int loop, (C) a loop that just builds strings, (D) an empty loop. Then the string time is
A-Cand the int time isB-D. Feel free to try this out if you want to dig deeper into the topic.#9 by Johnny Boy on February 12th, 2019
For performance reasons, this blog article ( http://cc.davelozinski.com/c-sharp/c-ints-vs-stringified-ints ) benchmarks some performance differences. In a nutshell, if you have relatively few keys and are using an object like a C# Dictionary, strings are faster; however, if you have 1000+ entries, ints are faster as keys by a factor of 10.
#10 by jackson on February 12th, 2019
It’s hard to compare AS3’s
Dictionaryto C#’sDictionary, so I won’t try here. I will say that I’d beware relying on the article you linked as it contains some critical errors. For example, at the outset the author states:In C#, strings are a managed class type containing at least an array of characters and a length. Characters are two bytes each, as you can see using
sizeof(char). The length is anint, which is four bytes. The class will likely also contain more data, such as in Unity’s IL2CPP whereObjectcontains two (4- or 8-byte) pointers. So even a one-character string is two bytes for the character, four bytes for the length, and more overhead depending on runtime implementation. At a minimum, it’s six bytes. Then you need to consider that theDictionarystores references to these strings, which are equivalent to a pointer at four or eight more bytes. In short, strings are always larger than ints. They also entail managed allocation, GC, and indirect memory reads to follow the pointer which will have CPU cache implications.