ActionScript Worker Message Passing is Slow
Since Flash Player 11.4 was released we have finally been given the ability to run multiple threads of AS3 code to take advantage of modern multi-core CPUs. However, when we start writing this multi-threaded code we immediately run into the requirement to coordinate the threads by passing messages between them. As it turns out, this is quite slow in AS3. Read on for the performance analysis.
The following test app performs a very simple task in two ways. The main thread passes a series of integers to a worker thread and the worker thread adds those integers together to compute their sum. Two ways of accomplishing this task are used. The first way passes 1000 individual messages to the worker thread, each with an integer to add. A final message is passed to tell the worker to pass the sum back to the main thread and clear for the next test. The second way of computing the sum creates a ByteArray with the shareable flag set to true. This ByteArray is then filled with all of the integers to sum and sent to the worker thread. The worker thread extracts these integers, adds them together, and passes a message back with the sum.
These two ways have been designed such that one passes a lot of messages and the other only passes one. Check out the source code for details.
package { import flash.display.Sprite; import flash.events.Event; import flash.utils.getTimer; import flash.utils.ByteArray; import flash.text.TextField; import flash.text.TextFieldAutoSize; import flash.system.Worker; import flash.system.WorkerDomain; import flash.system.WorkerState; import flash.system.MessageChannel; public class MessageChannelTest extends Sprite { private var logger:TextField = new TextField(); private function row(...cols): void { logger.appendText(cols.join(",")+"\n"); } private var mainToWorker:MessageChannel; private var mainToWorkerBytes:MessageChannel; private var mainToWorkerClear:MessageChannel; private var workerToMain:MessageChannel; private var worker:Worker; private var REPS:int = 100000; private var beforeTime:int; private var sum:int; private var correctSum:int; public function MessageChannelTest() { logger.autoSize = TextFieldAutoSize.LEFT; addChild(logger); if (Worker.current.isPrimordial) { startMainThread(); } else { startWorkerThread(); } } private function startMainThread(): void { worker = WorkerDomain.current.createWorker(this.loaderInfo.bytes); mainToWorker = Worker.current.createMessageChannel(worker); worker.setSharedProperty("mainToWorker", mainToWorker); mainToWorkerBytes = Worker.current.createMessageChannel(worker); worker.setSharedProperty("mainToWorkerBytes", mainToWorkerBytes); mainToWorkerClear = Worker.current.createMessageChannel(worker); worker.setSharedProperty("mainToWorkerClear", mainToWorkerClear); workerToMain = worker.createMessageChannel(Worker.current); workerToMain.addEventListener(Event.CHANNEL_MESSAGE, onWorkerToMainDirect); worker.setSharedProperty("workerToMain", workerToMain); worker.start(); for (var i:int = 0; i < REPS; ++i) { correctSum += i; } row("Type", "Time", "Correct?"); sum = 0; beforeTime = getTimer(); for (i = 0; i < REPS; ++i) { mainToWorker.send(i); } mainToWorkerClear.send(true); } private function startWorkerThread(): void { mainToWorker = Worker.current.getSharedProperty("mainToWorker"); mainToWorkerBytes = Worker.current.getSharedProperty("mainToWorkerBytes"); mainToWorkerClear = Worker.current.getSharedProperty("mainToWorkerClear"); workerToMain = Worker.current.getSharedProperty("workerToMain"); mainToWorker.addEventListener(Event.CHANNEL_MESSAGE, onMainToWorker); mainToWorkerBytes.addEventListener(Event.CHANNEL_MESSAGE, onMainToWorkerBytes); mainToWorkerClear.addEventListener(Event.CHANNEL_MESSAGE, onMainToWorkerClear); } private function onMainToWorker(event:Event): void { sum += mainToWorker.receive(); } private function onMainToWorkerBytes(event:Event): void { var bytes:ByteArray = mainToWorkerBytes.receive(); bytes.position = 0; var numInts:int = bytes.length / 4; var sum:int; for (var i:int; i < numInts; ++i) { sum += bytes.readInt(); } workerToMain.send(sum); } private function onMainToWorkerClear(event:Event): void { workerToMain.send(sum); sum = 0; } private function onWorkerToMainDirect(event:Event): void { sum = workerToMain.receive(); var afterTime:int = getTimer(); row("Direct", (afterTime-beforeTime), (sum==correctSum)); workerToMain.removeEventListener(Event.CHANNEL_MESSAGE, onWorkerToMainDirect); workerToMain.addEventListener(Event.CHANNEL_MESSAGE, onWorkerToMainBytes); var bytes:ByteArray = new ByteArray(); bytes.shareable = true; bytes.length = REPS*4; bytes.position = 0; sum = 0; beforeTime = getTimer(); for (var i:int; i < REPS; ++i) { bytes.writeInt(i); } mainToWorkerBytes.send(bytes); } private function onWorkerToMainBytes(event:Event): void { sum = workerToMain.receive(); var afterTime:int = getTimer(); row("ByteArray", (afterTime-beforeTime), (sum==correctSum)); } } }
I ran this test in the following environment:
- Release version of Flash Player 11.8.800.170
- 2.3 Ghz Intel Core i7
- Mac OS X 10.8.5
- ASC 2.0.0 build 353981 (
-debug=false -verbose-stacktraces=false -inline -optimize=true)
And here are the results I got:
| Type | Time |
|---|---|
| Direct | 2359 |
| ByteArray | 4 |
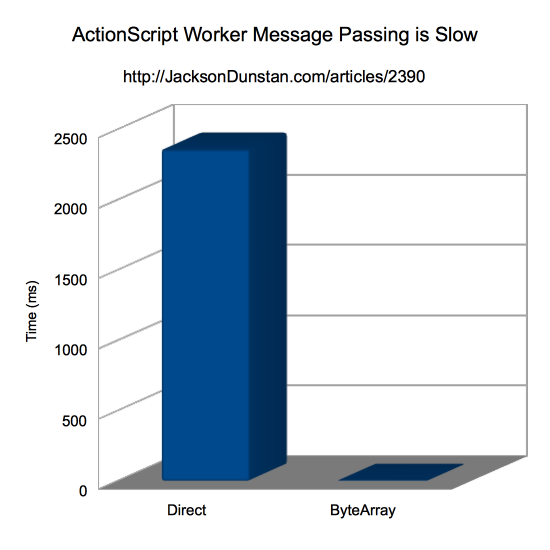
The ByteArray version is clearly leaps and bounds faster than the direct version that passes individual messages. In this test environment at least, each message is taking 0.02359 milliseconds. A mere 50 messages would eat up a whole millisecond of this relatively-fast CPU, probably far too much for a complex game that’s otherwise busy with 3D graphics, physics, and so forth. If you can, it’s much quicker to bundle up these messages into a ByteArray marked shareable and send them all over at once.
Spot a bug? Have a question or suggestion? Post a comment!
#1 by Troy on October 6th, 2013
Passing many messages appears to be inefficient, but does the size of what your passing have any effect on the throughput? I know that the object being passed over the channel is serialized/deserialized via AMF according to the documentation. I guess you have to weigh the cost of serialization to the savings of offloading the processing.
#2 by jackson on October 6th, 2013
Size will definitely have an impact. Thankfully,
ByteArray.shareableprovides a way to not copy the wholeByteArraybut instead only a reference to it.As for serialization and deserialization, you’re right that you’ll need to weigh that time against the benefits of using multiple threads. Hopefully you’ll be able to find some tasks that don’t involve a lot of inter-thread communication so the serialization process is minimal and the value of the extra threads is maximized.
#3 by Glidias on November 3rd, 2013
Yup, normally, the message i pass is a single integer representing an app-specific command/notification constant . Then, I have sharable bytearrays constisting of values and parameters. (eg. mainToWorkerParams, workerToMainPayload, workerToMainParams) which contains the bulk of the info. All the bulk is passed accordingly. However, I’m still currently passing an integer to signify the request type, (because i’m lazy to create multiple message channels even though I should…). Your benchmark is for the entire roundtrip right which includes multiple mainToWorker.send() calls? Can you do a single benchmark where mainToWorker only sends a single integer (or a single vector array of numbers) instead of using multiple mainToWorker.send() calls? I dunno, but multiple send() calls also seem to trigger the handler multiple times (dunno why..). What about a single call to mainToWorker.send() but using a vector/array of numbers instead? Normally, I only resort to sending a single integer value. In such a case, is the performance difference really that big?
Is channel.send(sharableByteArray) really necessary since the main/worker already saves their own copy of the bytearray in their relavant domain? You seem to pass a pointer to the sharableByteArray, can you just send a single dummy integer instead, assuming you already saved the references to the shared bytearrays already from both domains (primordial vs worker)? https://github.com/Glidias/Asharena/blob/master/src/arena/systems/islands/IslandChannels.as
In this case, I never use channel.send(sharedByteArray), since the shared bytearray references is already stored in this class holder which i instantiate on both ends. I assume sending a single pointer to the sharable bytearray or a dummy/notification-code integer should have not much difference in terms of performance.
One thing I realised/to take note (from my tests..i think…), is the sharable bytearray.position pointer seems different (ie. unshared) across the worker/main domains. I assume (based on my tests) that the .length getter/setter should be shared/affective across all domains, though, since it affects the bytearray data directly, but the position pointer ( and perhaps some other properties), may be domain-specific? I find myself having to reset the position pointer manually at different domains. Thus, it isn’t really a sharable Bytearray as in sharing the exact same reference???, but most probably sharing the same reference to the bytes in memory? Maybe i should do a strict equality check between the bytearray instances with receive() under Main versus the one in setSharedProperty() by main() to see if it matches (perhaps, for the case of using receive(), it will be a matching strict equality with matching position pointer??).
#4 by jackson on November 4th, 2013
Since each
send()/receive()pair is so fast, the test app in the article does 100,000 of them. You can then average the time by simply dividing by 100,000 to get a per-pair time. So the “direct” version is taking 0.02359 milliseconds per pair. That’s pretty quick if you’re only using one message per frame, whichMessageChannelrequires.Check out the followup article for more discussion of sharing directly via
setSharedProperty. The article after that discusses an even faster way that also directly usessetSharedProperty. These should serve as viable alternatives to directly passing aByteArrayviasend()andreceive()on aMessageChannel.As for the
lengthandpositionfields ofByteArray, I’ll need to look into that to find out more. I hadn’t considered sharing those fields before, just the contents of theByteArray.#5 by Glidias on November 6th, 2013
I confirmed that ByteArray instances and their fields are domain-specific, but the underlying byte data is shared. http://forums.adobe.com/message/5803611#5803611 . I’m can’t really be bothered to test if sending the ByteArray instance via channel and receiving it via channel.receive() will yield strict equality or not with the sharedProperty/getSharedProperty instances. Probably not.
I’m not sure how this plays with using alchemy domain memory across different workers. Do different workers have their own copy of domain memory? I assume so, ie. you can use Memory.select on different bytearrays for each worker? What if multiple workers use Memory.select() over a same sharable ByteArray? I’m considering of creating a GrayscaleBitmapData class in Haxe that uses Alchemy memory to make operations like sampling/intepolating grayscale height data faster for my app instead, since pure BitmapData or Vector uses up unnecessary bytes especially for grayscale images. Then, all you need is to pass a single address offset value between domains and some other parameters, in order to set/get numbers easily on both sides.
As mentioned in a later article, I’d probably consider using mutex rather than using messageChannel to act as a means to ping/pong notifications between workers/main. This may be a good way for Workers to work on Main data directly without additional main-specific parsing, which I should seriously consider (at least later when implementations are finalized and coupling is fine) in order to better optimize performance.
#6 by jackson on November 6th, 2013
Thanks for the confirmation about the
lengthandpositionfields. I figured they were worker-specific, but it’s good to test your assumptions.I’m not sure about the domain memory (“Alchemy”) opcodes, but I’d guess that using them is just the same as using plain AS3 since the
ByteArrayisn’t copied to domain memory, it’s just pointed to as the source of domain memory. That’s probably another good followup test though.#7 by Ellie Richardson on August 17th, 2014
Extremely exciting critique
#8 by zermok on July 13th, 2018
Unfortunately since Flash version 30
shareable bytearray has been disabled by default to mitigate the spectre and meltdown vulnrability affecting
90% of CPU on the market.
http://blogs.adobe.com/flashplayer/2018/06/fp-spectre.html#sthash.s1DL9caF.dpbs