An ASC 2.0 Domain Memory Opcodes Primer
Since January, Adobe has dropped the “premium features” requirement for Flash apps that use the “domain memory opcodes” (a.k.a. “Alchemy opcodes”) that provide low-level performance-boosting operations that let you deal more-or-less directly with blocks of memory. Then in February we got Flash Player 11.6 along with built-in ASC 2.0 support for this feature. Today’s article shows you how to use these opcodes and takes a first stab at improving performance with them. Are they really all they’re cracked up to be?
To use the “domain memory opcodes”, you first need to make sure your build environment is configured properly. If it’s not, none of the code below will work. For starters, you need to use ASC 2.0 as ASC 1.0 does not directly support these opcodes. You can get ASC 2.0 as part of the AIR SDK. I’ll leave configuring your IDE (e.g. Flash Builder) to you since there are far too many to discuss here. Second, you need to target Flash Player 11.6 by adding these command-line parameters (or the equivalent in your IDE):
--target-player=11.6.0 -swf-version=19
Now you’re ready to start using the “domain memory opcodes”. These exist as package-level functions inside avm2.intrinsics.memory which is automatically available to you without needing to link against any additional SWCs. You don’t need to worry about the function call overhead for these since ASC 2.0 will automatically replace these function calls with the equivalent domain memory opcodes. This means that there won’t be any function call overhead but you get to use nice AS3 functions rather than hand-typing assembly code. This is all very similar to Apparat and other tools’ original support for “Alchemy opcodes”.
Here’s what the avm2.intrinsics.memory package looks like:
package avm2.intrinsics.memory { public function li8(addr:int): int; // Load Int 8-bit public function li16(addr:int): int; // Load Int 16-bit public function li32(addr:int): int; // Load Int 32-bit public function lf32(addr:int): Number; // Load Float 32-bit (a.k.a. "float") public function lf64(addr:int): Number; // Load Float 64-bit (a.k.a. "double") public function si8(value:int, addr:int): void; // Store Int 8-bit public function si16(value:int, addr:int): void; // Store Int 16-bit public function si32(value:int, addr:int): void; // Store Int 32-bit public function sf32(value:Number, addr:int): void; // Store Float 32-bit (a.k.a. "float") public function sf64(value:Number, addr:int): void; // Store Float 64-bit (a.k.a. "double") public function sxi1(value:int): int; // Sign eXtend 1-bit integer to 32 bits public function sxi8(value:int): int; // Sign eXtend 8-bit integer to 32 bits public function sxi16(value:int): int; // Sign eXtend 16-bit integer to 32 bits }
You can use these like any other package-level function (e.g. flash.utils.getTimer):
import avm2.intrinsics.memory.li32; // import the function itself class MyClass { function foo(): void { // Get the 32-bit integer value at myAddr var val:int = li32(myAddr); } }
So what memory are these functions dealing with? Well, that’s the so-called “domain memory” attached to the current ApplicationDomain. Essentially, each SWF gets its own ApplicationDomain that defines its environment such as the classes that are available. When you load another SWF (e.g. an animation to show), that will get its own ApplicationDomain (subject to some Loader tricks). But for most purposes, you only need to deal with the current domain and can ignore all others. Here’s how you set up the “domain memory”:
import flash.system.ApplicationDomain; import flash.utils.ByteArray; import flash.utils.Endian; var myDomainMemory:ByteArray = new ByteArray(); myDomainMemory.length = 4*1024; // allocate at least a few KB to use with the opcodes myDomainMemory.endian = Endian.LITTLE_ENDIAN; // domain memory should always be little endian ApplicationDomain.currentDomain.domainMemory = myDomainMemory;
Now let’s see if we can use them to make some code run faster. Here I’ve just tested the first idea to come to mind: storing 32-bit floats in domain memory for faster uploading to Stage3D resources like VertexBuffer. Since there’s no 32-bit floating point type in AS3 (only the 64-bit Number), a Vector.<Number> needs to be converted by the CPU from 64-bit to 32-bit at upload time. Flash Player does this for us in native code, but it’s still slow. If we store the floats in a ByteArray as 32-bit then we can gain better control over the conversion process. For example, if we keep the ByteArray after uploading it then we can avoid 64-to-32-bit conversion again when we handle context loss.
Here’s a little app that tests storing some floating point values in a Vector.<Number> as well as “domain memory” as contiguous blocks of both 32-bit and 64-bit floating point values. The applicable domain memory opcodes to look for are sf32 and sf64.
package { import flash.utils.Endian; import avm2.intrinsics.memory.sf32; import avm2.intrinsics.memory.sf64; import flash.system.ApplicationDomain; import flash.utils.getTimer; import flash.utils.ByteArray; import flash.text.TextFieldAutoSize; import flash.display.StageScaleMode; import flash.display.StageAlign; import flash.text.TextField; import flash.display.Sprite; public class FillFloats extends Sprite { private var __logger:TextField = new TextField(); private function row(...cols): void { __logger.appendText(cols.join(",")+"\n"); } public function FillFloats() { stage.align = StageAlign.TOP_LEFT; stage.scaleMode = StageScaleMode.NO_SCALE; __logger.autoSize = TextFieldAutoSize.LEFT; addChild(__logger); init(); } private function init(): void { const SIZE:uint = 10000000; var i:uint; var vec:Vector.<Number> = new Vector.<Number>(SIZE); var domainMemory:ByteArray = new ByteArray(); domainMemory.length = SIZE*4 + SIZE*8; domainMemory.endian = Endian.LITTLE_ENDIAN; var floats:uint = 0; var doubles:uint = SIZE*4; var curAddr:uint; var beforeTime:int; var afterTime:int; ApplicationDomain.currentDomain.domainMemory = domainMemory; row("Storage", "Time"); beforeTime = getTimer(); for (i = 0; i < SIZE; ++i) { vec[i] = i; } afterTime = getTimer(); row("Vector", (afterTime-beforeTime)); beforeTime = getTimer(); curAddr = floats; for (i = 0; i < SIZE; ++i) { sf32(i, curAddr); curAddr += 4; } afterTime = getTimer(); row("Domain Memory (floats)", (afterTime-beforeTime)); beforeTime = getTimer(); curAddr = doubles; for (i = 0; i < SIZE; ++i) { sf64(i, curAddr); curAddr += 8; } afterTime = getTimer(); row("Domain Memory (doubles)", (afterTime-beforeTime)); } } }
I ran this test in the following environment:
- Release version of Flash Player 11.8.800.97
- 2.3 Ghz Intel Core i7
- Mac OS X 10.8.4
- ASC 2.0 build 352231 (
-debug=false -verbose-stacktraces=false -inline)
And here are the results I got:
| Storage | Time |
|---|---|
| Vector | 24 |
| Domain Memory (floats) | 27 |
| Domain Memory (doubles) | 26 |
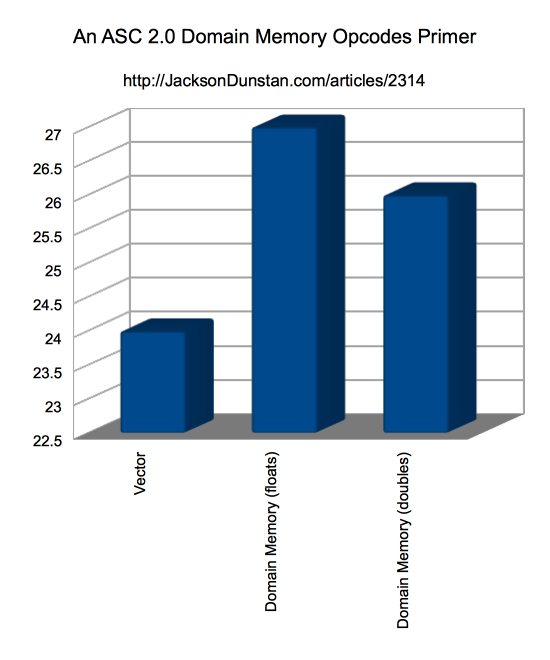
Performance of the domain memory opcodes is consistently close to the Vector performance, but never quite matches it. I’ve tried lots of variations (not shown) including assignment to random memory locations, pulling Number values out of a Vector instead of converting from an int (the iterator), using a Number-typed iterator, copying the floating-point values to store from another Vector or domain memory, doing more copies per loop iteration, using different browsers, and so forth. Regardless, Vector seems to beat out the domain memory opcodes in this case.
So while domain memory doesn’t shine here, that doesn’t mean that it has no purpose anywhere. There are several reports of it providing massive speedups in other cases. I’ll certainly keep looking for speedups using domain memory opcodes. In the meantime, there may also be a lot of variation between different types of hardware. Care to try it out and post your results in the comments?
#1 by Ignatiev on July 22nd, 2013
Windows 7, i5 @ 2.8GHz, 8Gb DDR2
Vector – 67
Domain Memory (floats) – 63
Domain Memory (doubles) – 64
Every time vector is a little bit slower.
#2 by Clark on July 22nd, 2013
Windows 7, i5 @ 2.67GHz, 4GB DDR3
Vector,53
Domain Memory (floats),62
Domain Memory (doubles),62
#3 by henke37 on July 22nd, 2013
Storage,Time
Vector,45
Domain Memory (floats),40
Domain Memory (doubles),55
#4 by Ben on July 22nd, 2013
Windows 7 64 Bit (i7-3770 @ 3.4 GHz; 32 GB RAM):
Vector,20
Domain Memory (floats),23
Domain Memory (doubles),22
#5 by ben w on July 22nd, 2013
Vector,50
Domain Memory (floats),49
Domain Memory (doubles),52
Also worthy of note that the bytearray tests have to perform an extra addition in every loop which may count against it (not by much I am sure but an extra cost it is)
It may also speed up your vector if you set the fixed flag to true when you create it.
b
#6 by jackson on July 22nd, 2013
That’s true about the extra addition, but it’s the cheapest way I could come up with to be able to write to the appropriate memory addresses. Something similar is likely going on behind the scenes for
Vector, but probably involves a multiply—addr = index*sizeof(element)— sinceVectorwrites are to random elements rather than the sequential writing optimization we get with domain memory.I didn’t try the
fixedflag since I’ve never noticed it actually yielding a performance improvement. For example, see Array vs. Vector.#7 by Smily on July 22nd, 2013
Windows 7 64-bit (Q6600 @ 2.6 GHz, 6 GB of slower RAM :))
Storage,Time
Vector,46
Domain Memory (floats),41
Domain Memory (doubles),48
I’ve applied ben w’s changes to the code and didn’t find much improvement until I changed from counting by one (either ++ or +1) to counting by 4/8. I even added additional operations to ensure that it’s still writing sequential numbers and at correct float and double starting addresses so the results would be consistent and fair. As a side-note, I don’t believe having a fixed vector significantly changed the results in this case.
It showed an improvement in speed of 10x (!!!) for doubles and 5x (!!) for floats with memory ops:
Storage,Time
Vector,45
Domain Memory (floats),8
Domain Memory (doubles),5
Here’s a compiled swf: https://dl.dropboxusercontent.com/u/14681/FillFloats.swf
This is definitely something worth investigating and might be related to aligned counting or some specific JIT optimizations, I’m not sure. Perhaps two differently aligned counters throw it off or something, but the key was to change
++i,i++ori += 1toi += 4ori += 8for floats and doubles respectively and change all the rest of the code to accommodate that.I was compiling for 11.7, but it’s unlikely that it would affect it, since I got the same results at first (unless the above optimization is unique to 11.7). Ran the tests with standalone release 11.7.700.178
Here’s the modified code (you can also press a key to repeat the test):
Here’s the build call:
I hope the code formatting worked right :)
#8 by jackson on July 22nd, 2013
I think the reason your domain memory versions run faster is that they’re only doing one-quarter and one-eighth as many float writes since you haven’t changed
SIZEbut you have skipped many values ofi.#9 by Smily on July 22nd, 2013
Well, that was stupid of me! It did seem fishy that it would drop like that from such a seemingly insignificant thing.
To make up for it, I tried a few more things.
I tried estimating the amount of time spent not writing anything (empty loop, just iteration and shared operations) which I then subtracted from all the results. It breaks down a bit with inconsistent timings, but I believe it’s more telling than taking the entire time.
I changed from having separate memory space for float and double to having a single space accommodating the largest type (double), so there are no offsets that you have to deal with. There might be some cache problems with that, but a large enough storage size should probably bust that?
I also separated the amount of iterations and the size of storage to see how they affect the outcome. Index positions wrap around to the beginning. Size might be relevant (the bigger it is, the larger the difference seems to become). Number of iterations maybe not so much (although the number of passes probably plays a role in it). This is all a bit hard to test due to overhead, could be in my head.
I added read times as well as writing/reading uint32 and uint8 types (si32, li32, si8, li8). I noticed significantly faster results for both uint8/32 reads, float/double reads too, but less so.
I then duplicated the operation 5 times to lower the overhead and noticed even more interesting things. This isn’t the same operation anymore (since it’s writing/reading the same bytes 5 times in a row), but the times between Vector and Domain Memory diverged even more, especially for read times across the board.
In summary, reading seems to be slow(er) with Vectors, especially with uints. Overhead is hard to measure in general, so other conclusions are hard to make.
Here’s the modified modified version (might take a few seconds): https://dl.dropboxusercontent.com/u/14681/FillFloats2.swf
Hopefully I didn’t mess up too much this time (forgive me if I did it again D:), but here are some of my results:
From above swf: https://dl.dropboxusercontent.com/u/14681/FillFloats3.png
Comparison between various sizes and a large iteration count: https://dl.dropboxusercontent.com/u/14681/FillFloats2.png
Code (might be getting a bit long :P)
#10 by jackson on July 22nd, 2013
Wow, that’s a lot of experimenting. Consider yourself redeemed. ;-)
Here are my results using the computer from the article:
So I’m always getting slower domain memory reads and faster domain memory writes. That’s an interesting result though since the article only has writing and domain memory was slower for me there. Perhaps it has to do with always writing to the same domain memory address, which may be optimized at some level: compiler, JIT, CPU. Speaking of, we do have very different CPUs. Yours is a Core 2-era CPU from 2007 and mine is an Ivy Bridge-based CPU from 2012. It’s possible that the difference is buried all the way down at the CPU level, or perhaps at the RAM level since we are hammering the RAM. Mine is 1600 MHz PC3-12800 DDR3L SDRAM and you list yours as “slower”, so perhaps the difference is there. We also have different operating systems, so there’s yet-another possibility.
In any case, it’s safe to say that “your results will vary”. In this case, dramatically.
#11 by Smily on July 22nd, 2013
Those are some… interesting results. I’m pretty sure those results mean that your domain memory reads are like.. super fast. So fast in fact that it throws off the empty loop subtraction thing, because you often get reads that are faster than an empty loop (which is odd in itself).
In an ideal situation, negative values (for the last three columns) shouldn’t actually happen, since a -41.41x speedup doesn’t mean that it’s slower (that would be something like 0.5x for twice as slow). It means that the whole logic broke and the loop was actually faster than the empty loop.
Maybe you could try setting the affinity or priority of the flash player for more consistency, but I didn’t experience a big difference there. I mean, I did get the occasional run where the empty loop was occasionally slower and it threw it off, but never by that amount. I was also thinking of running a warmup loop that just runs for a couple of seconds if frequency scaling takes a bit to kick in (which would probably affect the timing) or something, but the results seem pretty apparent and even more skewed towards what I found – marginally faster writes, but a lot faster reads. You could say immeasurably fast reads even :)
If you have the time, what I’d suggest is taking the code and upping the iteration count to at least 5e7 or 1e8 and maybe trying to change the size to see if that affects it (keep to powers of 2). Reads on your system seem very odd though.. doing something faster than not doing it is a bit disconcerting to say the least. Perhaps we invented time travel or at least broke the fundamental axioms of logic. More likely my code is just shit ;P
#12 by jackson on July 23rd, 2013
I’ve done some “compare with a base version” type of testing before and find negative number results all the time. The tests will naturally vary in performance and it’s really important to test them repeatedly to get high-quality results. This, unfortunately, means that “base version” tests are quite unreliable. I therefore don’t use them anymore.
#13 by Tyler Seitz on July 26th, 2013
Hey Smily and Jackson, recently I have been teaching myself stage3d. And by no means have as well of a grasp on it as either of you do. I have so far managed to create a simple render of a few cubes with an interactive camera following Jackson’s simple stage3d camera article. http://www.fastswf.com/0ubMhiM
What I am curious is to how you, Smily have managed to render so many voxels in videos like this: http://www.youtube.com/watch?v=z-EZKsOuaEM
I feel like I am missing some sort of technique to simplify and optimize the drawing process. Another thing that has bothered me is that in most tutorials or examples I have found around the internet vertices aren’t shared in meshes, is there a specific reason for this? or is it dependent on the uv coordinates? If either of you could get back to me that would be great :)
#14 by jackson on July 26th, 2013
Well, you always have an index buffer but those indices are shared among all vertex buffers you draw with. So if you have a vertex (say a corner of a cube) that’s shared with several (six) triangles, it may have different texture/UV coordinates for each triangle. This means you can’t share the same position/XYZ for each triangle because that position shares an index with a single texture coordinate. Unfortunately, this means you need to duplicate the position in its vertex buffer once for each time corresponding vertex buffers (like texture coordinates) differ. Or if you’re interleaving (mixing them all into one vertex buffer) then the same applies there.
In the end the drawing process should be incredibly simple and optimal: set shader, index buffer, and vertex buffers, then call
drawTriangles. The GPU will dutifully chug through your triangles and render them with tremendous efficiency. With a simple shader (e.g. just a matrix transform and texture sample) and minimal overdraw, you should be able to pull off tens or hundreds of thousands of triangles even on low-end hardware like iPad 1. If not, you have room for optimization somewhere. :)#15 by Tyler Seitz on July 26th, 2013
Thanks for getting back to me so fast, I am currently following the same process and have been able to draw over 100,000 triangles at approximately 30 frames per second; however where I seem room for improvement is in the number of
drawTrianglescalls that being made. Is there not a way to group together the cubes into a chunk of sorts? Because at the moment if I want to create a 16x16x16 chunk of cubes the gpu has to draw 12 triangles, stop, then repeat the process for the rest of the cubes. Is it possible to simply combine the cubes to simply call onedrawTrianglescall for every 16x16x16 chunk of cubes? I have seen this process done in other languages and want to see if I can make use of the technique flash.#16 by jackson on July 26th, 2013
Ah, yes that would be very inefficient. A much better approach would be to concatenate all of the cubes into a giant index buffer and giant vertex buffer(s). Then you can just call
drawTrianglesonce and render them all. You will need to, of course, change the positions of the cubes so that they don’t all overlap. You can do this on the CPU in AS3 by changing the data before you upload it to the vertex buffer or on the GPU in AGAL by applying some transformation on a per-vertex basis. The latter is better suited for dynamic cube fields (e.g. where they all rotate) and the former is better suited for static cube fields (where they just sit there) because it has requires shader instructions and less data passing to the GPU (e.g. via constants/uniforms). What you don’t want to do is change all the positions in AS3 every frame and re-upload the whole thing. The upload process is expensive and your framerate would suffer tremendously.#17 by Tyler Seitz on July 26th, 2013
How would I go about chaining together the cubes into giant buffers without calling the
uploadFromVectorfunction for each cube? Would that not also be an expensive process? I also have not worked with AGAL that much either and do not know how to apply transformations per vertex. It seems like an over complicated process for a concept quite simple. To get more of an idea on how I would chain together the cubes on the gpu, how would I create a 2×2 cube and position the cubes on the gpu?#18 by jackson on July 26th, 2013
To keep the example small, say you have just two triangles you want to chain together. You’d have two vertex buffers:
1, 2, 3
4, 5, 6
To chain them together, simply concatenate your
Vector.<Number>orByteArrayso you have:1, 2, 3, 4, 5, 6
Then upload the whole thing at once.
Transforming the vertices on the GPU (e.g. with AGAL) is definitely much more complex than transforming them in AS3. You really have to think differently and do some tricky work to get that version working. You’d almost be implementing a skeletal animation system, which employs similar strategies when implemented on the GPU.
Stage3Dwas designed to give Flash developers low level access to the GPU and is therefore difficult to use for even simple purposes like efficient drawing of a few cubes. If you want to useStage3Ddirectly you’re going to have to get used to this level of complexity. If you’d rather not get used to it, you should check out engines that make this simpler: Away3D, Starling, Flare3D, Alternativa3D, ND2D, etc. You’ll lose lots of flexibility and low-level optimization opportunities, but the simplicity and time savings are undeniable for most projects.#19 by Tyler Seitz on August 2nd, 2013
Thanks for the help :) I took the time to go over concatenating vertices and splitting the buffers. It took me a while but I managed to get a new demo running, thanks to an old package Smily had linked to in one of his youtube videos.
http://www.fastswf.com/JGIop40
Controls: WASD SPACE SHIFT MOUSE (a bit touchy on the y axis)
I’m gonna take this technique now and see what sort of 3 dimensional shapes I can conjure up.
#20 by jackson on August 2nd, 2013
Glad to see you’ve got it working. 280,000 triangles is a lot better. :)
For some shapes you can make in code, check out Procedurally-Generated Shapes Collection
#21 by Andrew on August 18th, 2013
Hi
Your code snippet is measuring the amount of time taken to write lots of data, either into a vector of double/Number types, or into the domain memory as a byte array.
But the article talks about the potential performance gain when using this for something that takes single-precision floating points, like the OpenGL ES implementations of Stage3D on Android or iOS.
So have you actually measured the time taken for uploadFromByteArray vs uploadFromVector for a VertexBuffer3D object? In all your above examples there is going to be some sort of format translation going on, but it would be interesting to see the potential gain when you just use bytearray rather than having the additional double-to-float translation when using Vector….
Thanks
Andrew
#22 by jackson on August 18th, 2013
Hi Andrew,
There’s a link in this article to the Stage3D Upload Speed Tester article where my performance data shows that uploading from
ByteArraycan be much quicker than other AS3 types likeVector.-Jackson
#23 by Andrew on August 18th, 2013
Thanks – I hadn’t spotted that hyperlink, sorry!
Impressive results, definitely worth taking a small hit at this stage if you then get such good upload rates!
Thank you
Andrew
#24 by Nikita on December 18th, 2013
Hello. I’m trying to use this package but with no luck. avm2.intrinsics.memory simply don’t have memory opcodes. The article from adobe says:
“Note: The memory intrinsic APIs are available as part of the compiler (ASC2) package. To make use of the APIs, ensure that you use Flash Builder to build your applications. The compiler package with the APIs are not available for use in IDEs other than Flash Builder.”
What IDE did you use? Does opcodes available with latest sdk?
#25 by jackson on December 18th, 2013
I think I had the same errors that you do, but they were solved with the advice I give at the beginning of the article:
I didn’t use any IDE for the code in this article. Instead, I directly used MXMLC from the command line. However, the basic settings should apply to any IDE:
#26 by Nikita on December 19th, 2013
I’ve used 3.9 and 4.0 beta. Target 11.6 player with 19 swf version and 11.9 player with 22 swf version. Compiled with mxmlc with command line, with FD and with IntelliJ. In every case I have “Variable avm2.intrinsics.memory::sf32 is not defined.”. There’s no autocompletion for fast opcodes – only casi32() and mfence() are available. There’s no definitions for fast opcodes functions in swc’s. Maybe you need specific swc? Maybe some swc from previous beta?
#27 by jackson on December 19th, 2013
I just tried using AIR 3.9 and it worked with the same command line parameters as in the article:
I’m not sure exactly how to get IntelliJ or FD to target 11.6 (or above), but I’m sure there’s some way in the project configuration settings. Of course, you’ll also need download and install the appropriate playerglobal.swc files in your AIR SDK, too.
#28 by Nikita on December 20th, 2013
Thank you. Yes, it works. Even without target-player and swf-version (because I compiled for 11.9 by default). The previous problem was that I tested availability of opcodes like this:
trace(avm2.intrinsics.memory.sf32); // expected “function Function() {}”
And this causes an error (even in yours code). So it seems that it’s a mandatory to use full function call. Simply sf32 won’t work, interesting why?